Show the packages used
library("groundhog")
packages <- c(
"here",
"tidyverse",
"tidytext",
"wordcloud",
"retrodesign",
"lubridate",
"DT",
"kableExtra",
"knitr",
"skimr",
"ggridges",
"mediocrethemes",
"fixest",
"modelsummary"
# "vincentbagilet/mediocrethemes"
)
# groundhog.library(packages, "2022-11-28")
lapply(packages, library, character.only = TRUE)
set_mediocre_all(pal = "leo")In this document, we carry out a retrospective power analysis to evaluate whether the literature on the short-term health effects of air pollution is prone to low power issues. Using REGular EXPressions (regex), we retrieved the estimates and confidence intervals displayed in the abstracts of relevant articles found in PubMed and Scopus (see this document for details on the procedure).
This notebook is organized as follows:
- We first explore the characteristics of the articles retrieved.
- Since we only retrieve effects for a subset of papers (i.e., those that displayed point estimates and confidence intervals in the abstract), we assess whether these papers are representative of the whole literature.
- We then explore the effects retrieved before carrying out the retrospective power analysis.
- We finally explore potential sources of heterogeneity in low power issues.
Articles Characteristics
We retrieved the articles from PubMed and Scopus using the following query on May 18, 2021:
‘TITLE((“air pollution” OR “air quality” OR “particulate matter” OR ozone OR “nitrogen dioxide” OR “sulfur dioxide” OR “PM10” OR “PM2.5” OR “carbon dioxide” OR “carbon monoxide”) AND (“emergency” OR “mortality” OR “stroke” OR “cerebrovascular” OR “cardiovascular” OR “death” OR “hospitalization”) AND NOT (“long term” OR “long-term”)) AND “short term”’
This query enables us to retrieve 1834 abstracts.
Themes
We display the main themes of the articles using a wordcloud:
Show code
abstracts_and_metadata %>%
unnest_tokens(word, abstract, to_lower = TRUE) %>%
anti_join(tidytext::stop_words, by = "word") %>%
count(word) %>%
with(wordcloud::wordcloud(
word,
n,
max.words = 80,
random.color = TRUE,
colors = "black"
))
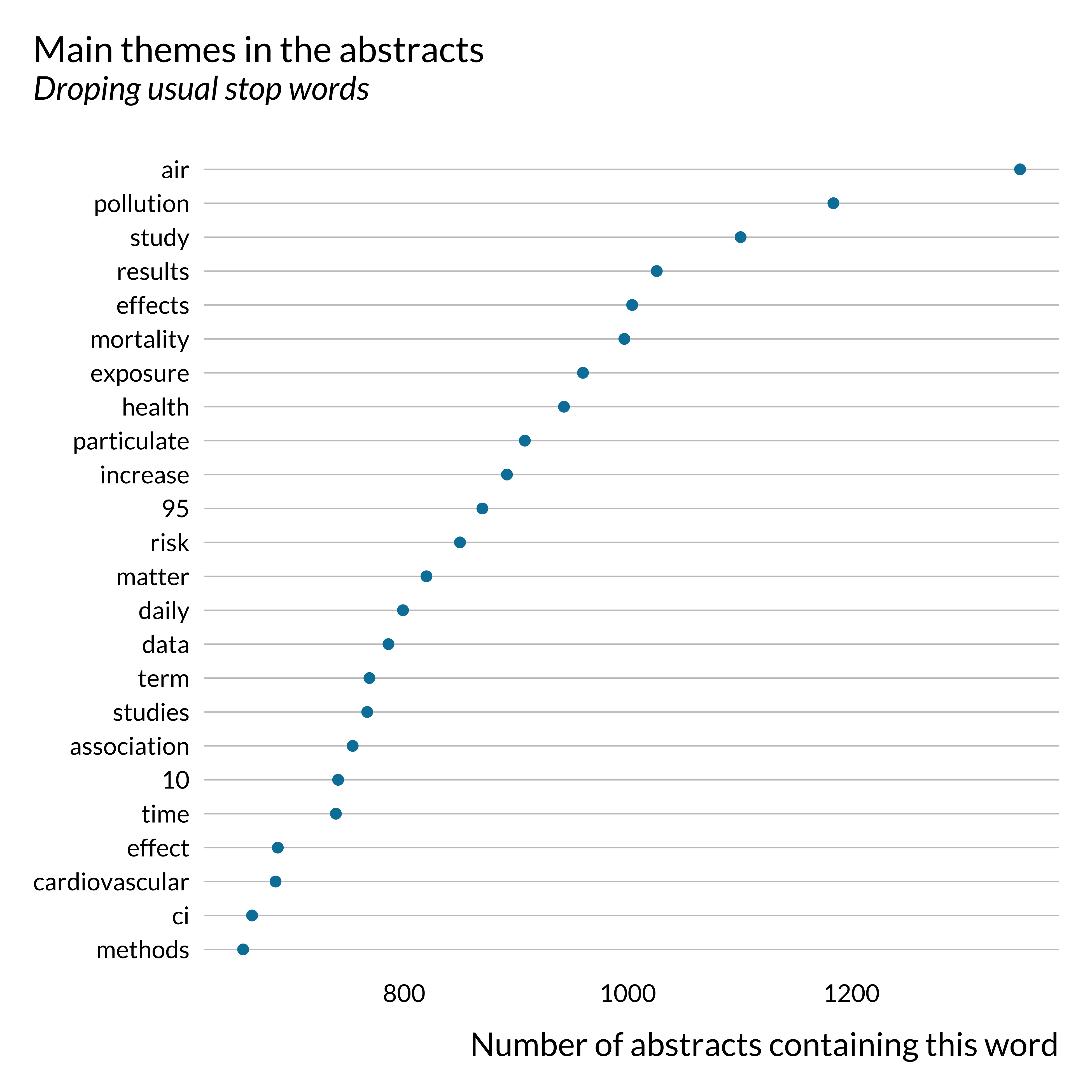
And we display the list of words the most frequently used:
Show code
abstracts_and_metadata %>%
unnest_tokens(word, abstract, to_lower = TRUE) %>%
anti_join(tidytext::stop_words, by = "word") %>%
select(doi, word) %>%
distinct() %>%
count(word, sort = TRUE) %>%
filter(n > 650) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_point(size = 2) +
labs(
y = NULL,
title = "Main themes in the abstracts",
subtitle = "Droping usual stop words",
x = "Number of abstracts containing this word"
) 
Detection of Effects
Show code
string_confint <- str_c(
"((?<!(\\d\\.|\\d))95\\s?%|(?<!(\\d\\.|\\d))95\\s(per(\\s?)cent)|",
"\\bC(\\.)?(I|l)(\\.)?(s?)\\b|\\bPI(s?)\\b|\\b(i|I)nterval|",
"\\b(c|C)onfidence\\s(i|I)nterval|\\b(c|C)redible\\s(i|I)nterval|",
"\\b(p|P)osterior\\s(i|I)nterval)"
)
effect_detected <- abstracts_and_metadata %>%
left_join(estimates, by = "doi") %>%
mutate(
contains_CI = str_detect(abstract, string_confint)
) %>%
group_by(title) %>%
mutate(
has_effect = (sum(!is.na(effect), na.rm = TRUE) > 0),
has_effect_phrase = ifelse(has_effect, "Effect retrieved", "No effect retrieved")
) %>%
ungroup() %>%
select(-effect, -low_CI, -up_CI) %>%
distinct()Out of the 1834 articles returned by the query, only a fraction reports estimates and confidence intervals in their abstracts. This might create some selection, making the sample of articles studied not representative of the whole literature. We investigate further the difference between articles that do and do not report confidence intervals in their abstracts in the following section.
We detect 2666 effects and associated confidence intervals. We retrieve estimates for most of the articles mentioning “confidence interval” in some forms in the abstract:
Show code
effect_detected %>%
filter(contains_CI) %>%
count(has_effect) %>%
mutate(
prop = round(n/sum(n)*100, 0),
has_effect = ifelse(has_effect, "Yes", "No")
) %>%
arrange(desc(has_effect)) %>%
kable(
col.names = c("Effect retreived", "Number of articles", "Proportion (%)"),
caption = "Number of articles for which at least one effect is retrieved (out of those containing the phrase 'CI')"
) %>%
kable_styling(position = "center")| Effect retreived | Number of articles | Proportion (%) |
|---|---|---|
| Yes | 784 | 88 |
| No | 110 | 12 |
Note that some abstracts contain the phrase “CI” without actually displaying effects and confidence intervals. Our algorithm seems to make a reasonably good job at detecting effects and CI when they are indeed displayed in an abstract. In addition, there is no reason to think that our ability to detect an effect would be correlated with power issues in the paper. Hence, we feel rather confident assuming that our detection algorithm selects a random (along our dimension of interest) sample of estimates among all estimates displayed in abstracts.
However, the initial query also returned articles that do not correspond to the type of papers we want to study. For instance, some articles look at the impact of air pollution on animal health. Other articles returned by the query are actually studying long term effects. We therefore skimmed through all the titles and abstracts for which an effect was retrieved and created a dummy variable describing whether these articles should be included in the analysis or not.
Show code
effect_detected %>%
filter(has_effect) %>%
count(valid) %>%
mutate(prop = round(n / sum(n)*100,0),
valid_effect = ifelse(valid, "Yes", "No")) %>%
arrange(desc(valid_effect)) %>%
select(valid_effect, n, prop) %>%
kable(
col.names = c("Valid article", "Number of articles", "Proportion (%)"),
caption = "Number of articles that display astimates and correspond to our study criteria"
) %>%
kable_styling(position = "center")| Valid article | Number of articles | Proportion (%) |
|---|---|---|
| Yes | 668 | 82 |
| No | 147 | 18 |
We therefore manually filter out 18.0368098% of the articles for which we retrieved an effect.
Overall, our corpus is composed of 668 articles for which we detect 2155 estimates.
Here is the list of the valid articles.
Representativity of Articles for which an Effect was Retrieved
In this subsection, we investigate whether there are systematic differences between articles for which we retrieved an effect and articles that do not display an effect in their abstract or for which we did not detect one. We build this analysis such that it also provides general information about the entire set of articles.
Note that we manually selected articles that correspond to the type of articles we are interested in this study, i.e., those investigating the short-term health effect of air pollution, only from the sample of articles for which we detected an effect. Hence, for articles where no effect was detected, we did not perform the manual filtering. In this section, we consider the full set of articles, which includes articles that we end up manually filtering out. The fact that the set of articles considered here is larger than the final set is not problematic because the present section mainly aims to evaluate the quality of our detection algorithm. We do not expect the algorithm to perform widely differently for articles that look at similar but slightly different questions than ours.
Qualitative Analysis
We skim through abstracts for which we retrieve an effect or not to see whether there are clear differences across study subsets.
First of all, we notice that we did not select some papers displaying effects in their abstracts because they do not mention confidence intervals. We need standard errors to compute power, exaggeration and type S error, hence why we did not select these papers. A small part of them seem to however mention p-values. We could have build on this to increase slightly our set of articles considered but it would not have drastically increased the set of articles considered. As discussed previously, we also acknowledge that our algorithm fails to detect a small share of otherwise valid estimates.
We then noticed that a non-negligible share of articles for which we do not detect an effect seem to to be off-topic. Our quick exploration did not show evidence of such an issue in articles for which we detected an effect. This is rather reassuring; we are filtering out not well-suited papers.
Finally, part of the studies for which we do not detect an effect are meta-analyses (based on a quick regex search, there are about twice has much metanalyses in articles with an effect).
Publication date
Getting back to our automated analysis, we first look into the distribution of published articles on this topic in time. We also wonder whether displaying effects in the abstract was a particular feature of a given period.
Show code
effect_detected %>%
# filter(contains_CI) %>%
ggplot() +
geom_density(aes(x = year(pub_date), color = has_effect_phrase), fill = NA) +
labs(
title = "Distribution of publication year",
subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Publication year",
y = "Density"
) +
scale_color_discrete(name = "")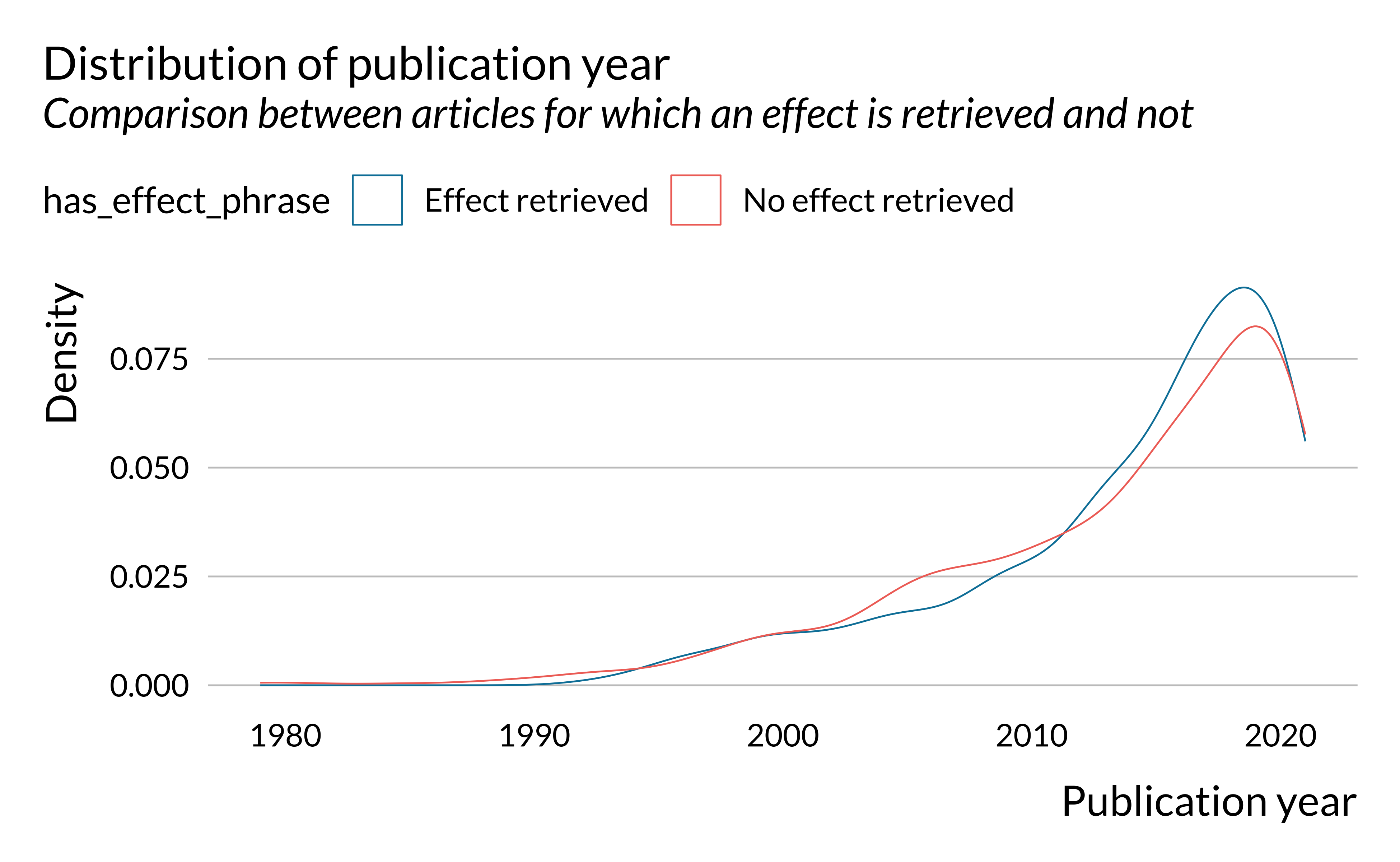
First, we notice that the number of articles published on short-term health effects of air pollution has been increasing rather strongly since the 1980s. The first article for which an effect is detected was published in 1992. We only found 12 articles published before 1992. This can be explained by the fact that, in most places, air pollution has only been measured consistently since the 1990s.
Even though there are slightly more recent (2010-2020) articles for which effects are retrieved, the difference does not seem to be substantial. Distributions of articles for which an effect has been retrieved and not are rather similar.
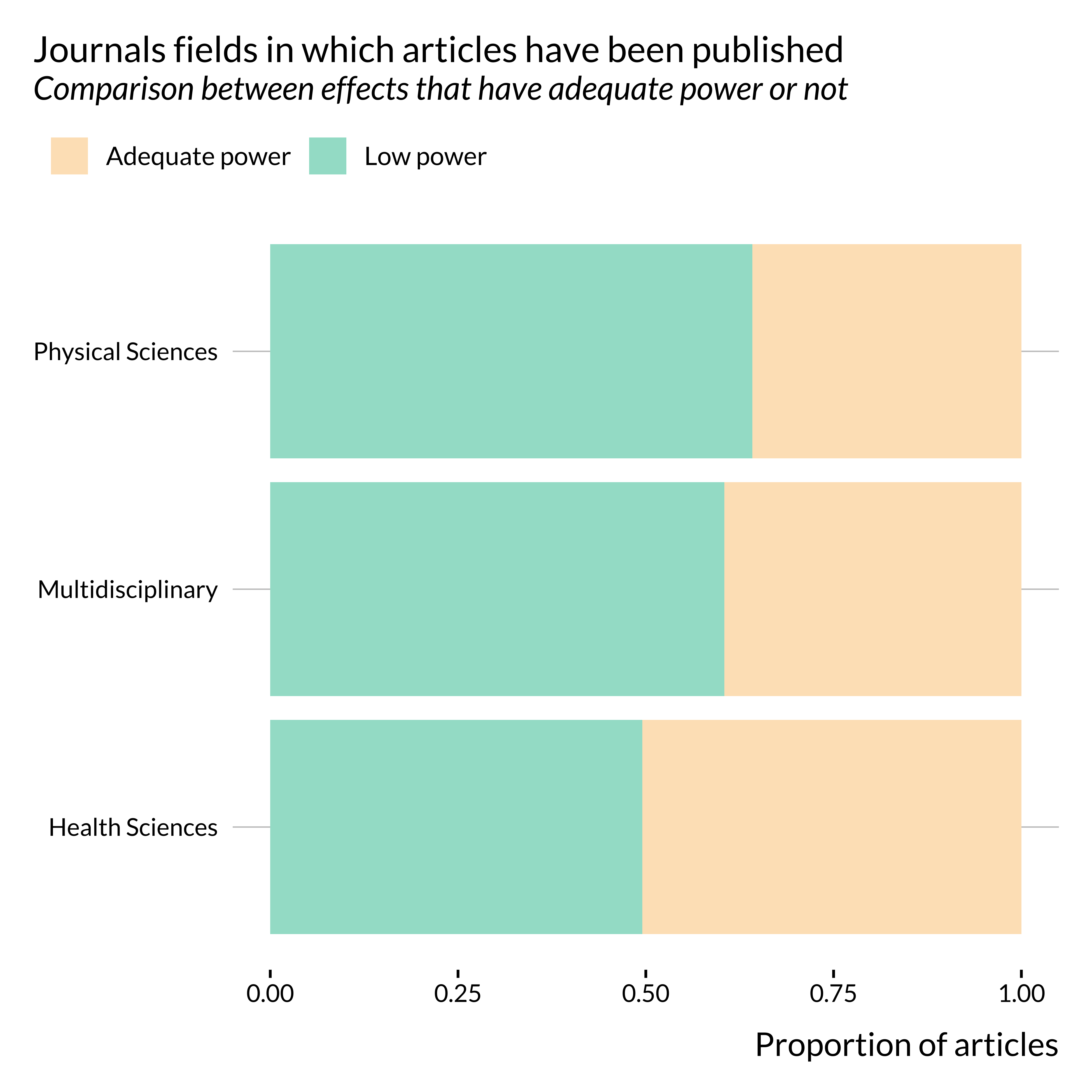
Journal and Fields
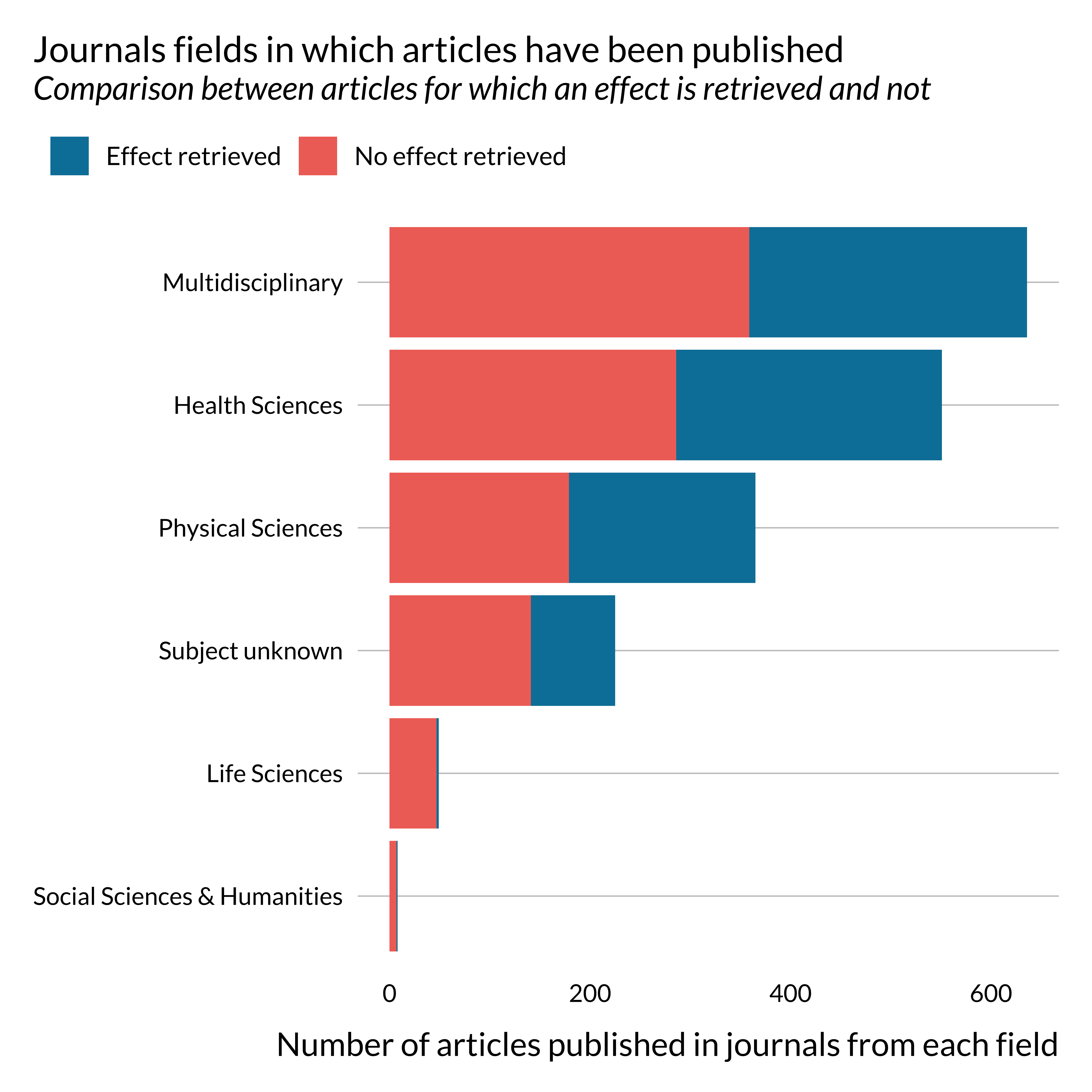
We then look into the journals and academic fields in which articles on short term health effect of air pollution have been published. The results by journals are rather messy so we focus on journal areas and subareas.
Show code
effect_detected %>%
mutate(
subject_area = ifelse(
is.na(subject_area),
"Subject unknown",
subject_area
)
) %>%
ggplot() +
geom_bar(aes(y = fct_rev(fct_infreq(subject_area)), fill = has_effect_phrase)) +
labs(
x = "Number of articles published in journals from each field",
y = NULL,
title = "Journals fields in which articles have been published",
subtitle = "Comparison between articles for which an effect is retrieved and not",
fill = ""
) 
Show code
effect_detected %>%
unnest(subsubject_area) %>%
mutate(
subsubject_area = ifelse(
is.na(subsubject_area),
"Subsubject unknown",
subsubject_area
)
) %>%
mutate(subsubject_area = fct_lump_n(subsubject_area, 20)) %>%
filter(subsubject_area != "Other") %>%
ggplot() +
geom_bar(aes(y = fct_rev(fct_infreq(subsubject_area)), fill = has_effect_phrase)) +
labs(
x = "Number of articles published in journals covering a given subsubject",
y = NULL,
title = "Main journals subsubjects in which articles have been published",
subtitle = "Comparison between articles for which an effect is retrieved and not",
caption = "A paper published in a multi-subject journal will appear several times",
fill = ""
) 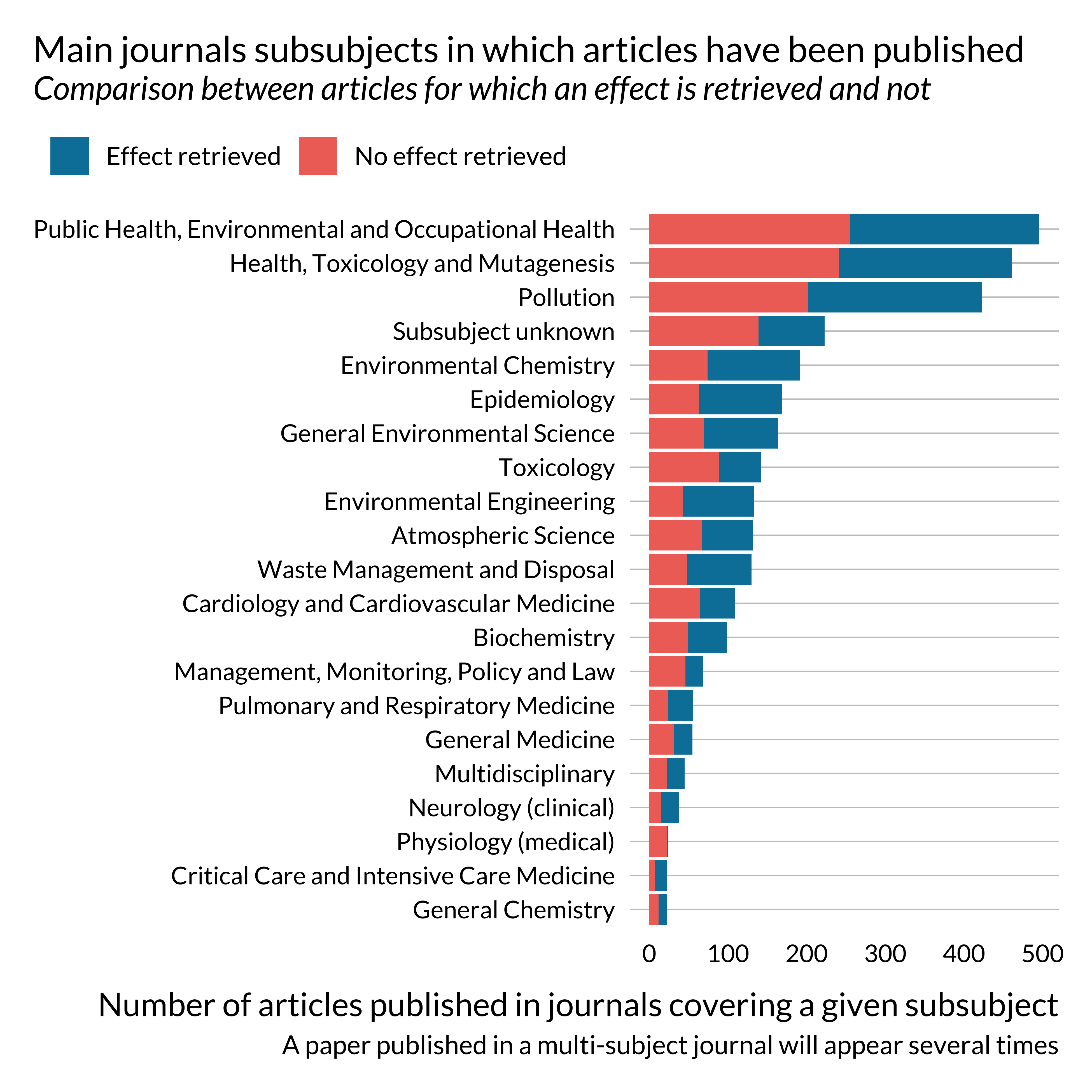
Most papers on this topic have been published in multidisciplinary journals or health science journals.
One may notice that effects are not retrieved, i.e., not reported in the abstract or not detected, for most papers published in life science and social sciences and humanities. This is probably due to reporting practices peculiar to these fields. This might not be as problematic as they constitute a small share of the sample. There does not seem to be a particularly large imbalance in terms of journal general field for the more represented fields.
Themes
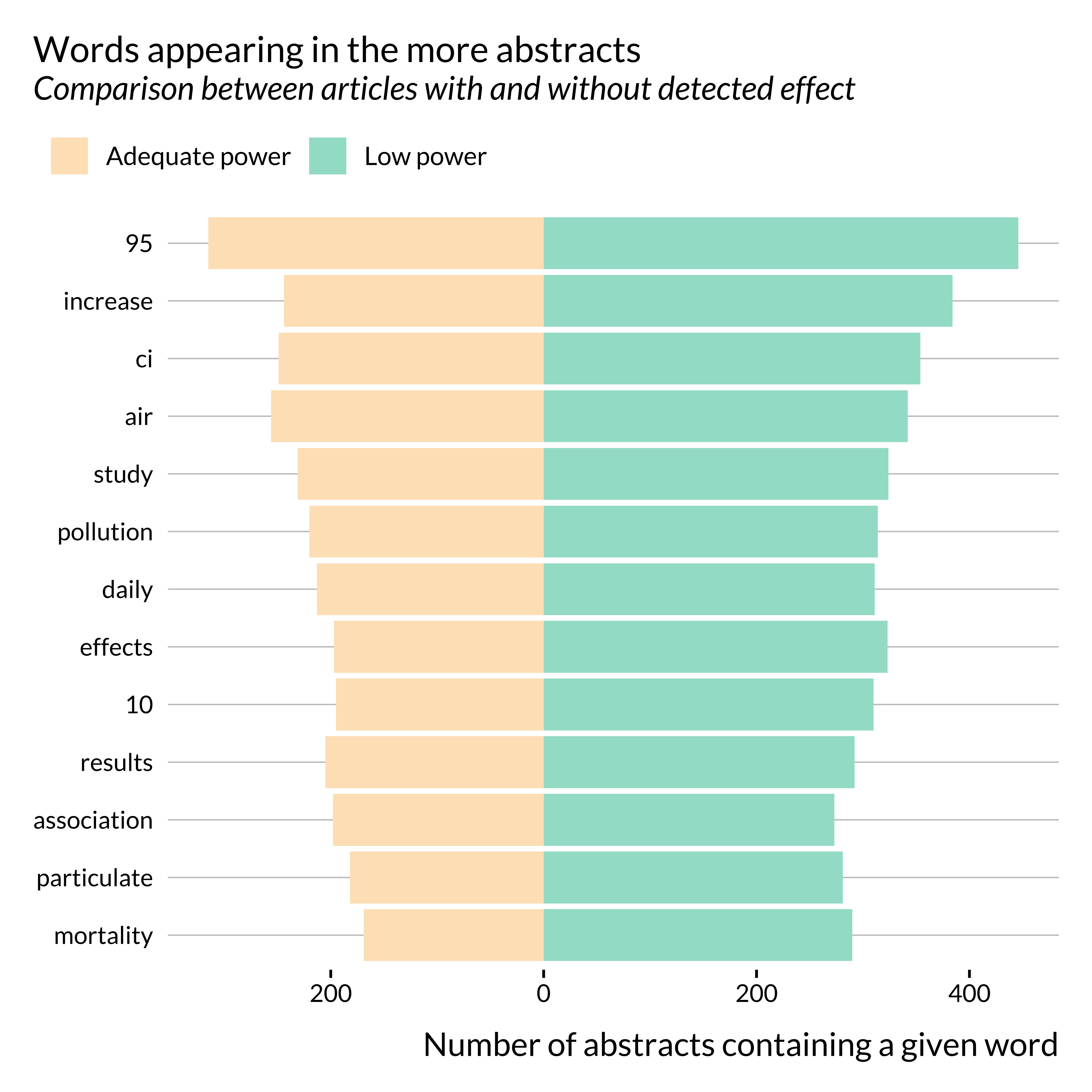
We then wonder if the words used in each sets of abstracts differ between the two sets of articles.
Show code
theme_effect <- effect_detected %>%
unnest_tokens(word, abstract, to_lower = TRUE) %>%
anti_join(tidytext::stop_words, by = "word") %>%
group_by(word, has_effect) %>%
mutate(n_articles_word = length(unique(doi))) %>%
ungroup() %>%
select(word, has_effect, has_effect_phrase, n_articles_word) %>%
distinct() %>%
group_by(word) %>%
mutate(tot_n_articles_word = sum(n_articles_word, na.rm = TRUE)) %>%
ungroup() %>%
filter(tot_n_articles_word > 600) %>%
ungroup() %>%
# mutate(has_effect = ifelse(has_effect, "Effect detected", "Effect not detected")) %>%
mutate(word = reorder(word, n_articles_word))
theme_effect %>%
ggplot(aes(x = word, fill = has_effect_phrase)) +
geom_col(
data = subset(theme_effect, has_effect),
aes(y = n_articles_word)
) +
geom_col(
data = subset(theme_effect, !has_effect),
aes(y = -n_articles_word),
position = "identity"
) +
scale_y_continuous(labels = abs) +
coord_flip() +
labs(
x = NULL,
y = "Number of abstracts containing a given word",
title = "Words appearing in the more abstracts",
subtitle = "Comparison between articles with and without detected effect",
fill = ""
) 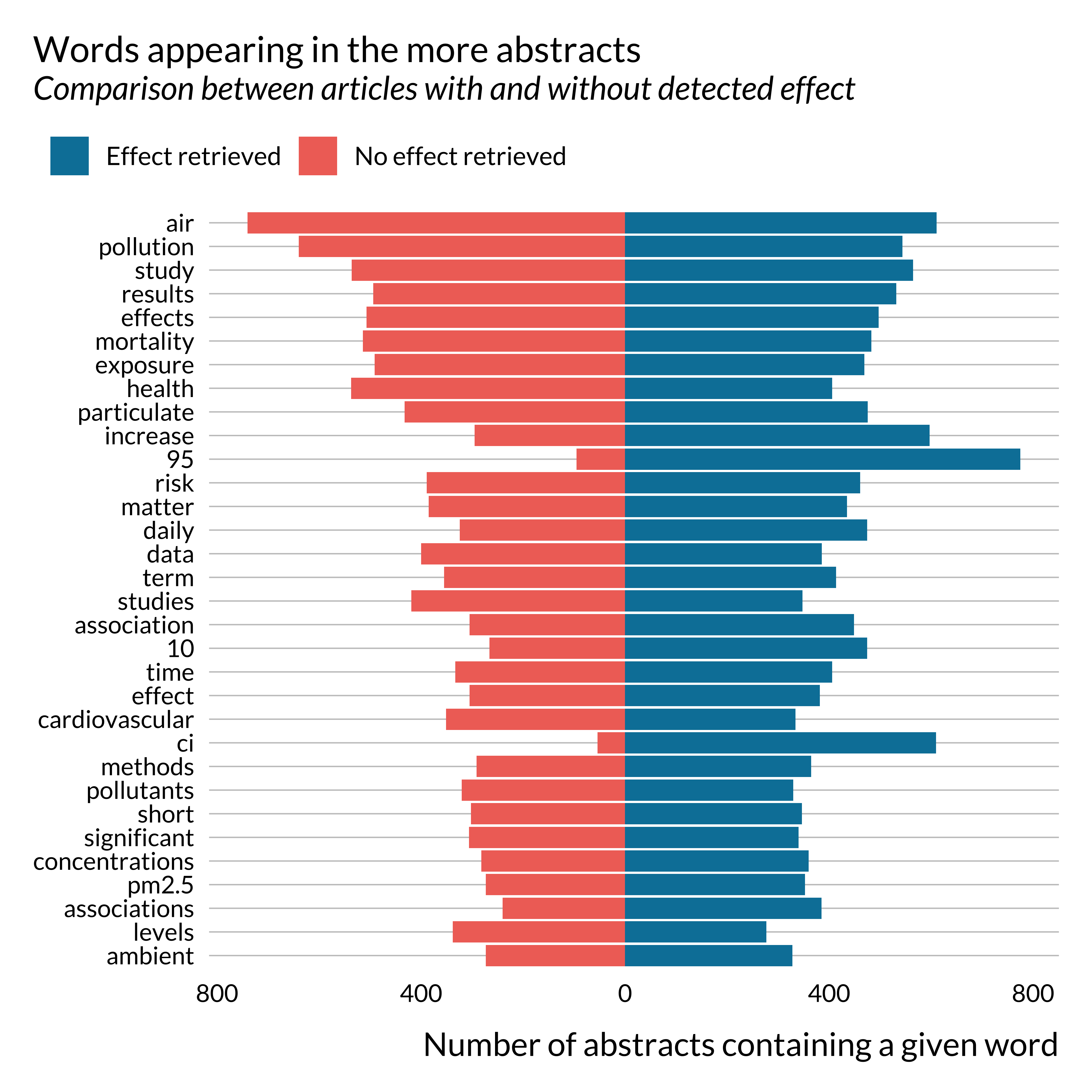
Apart from a few key terms, such as CI, 95 for instance, there are no huge differences in the terms used in both subsets of abstracts. Noticeably, the term “increase” seems to appear more in abstracts where we detect an effect. This is not surprising as these papers often use sentences similar to “a 10 \(\mu g/m^{3}\) increase in PM\(_{10}\) concentration is associated with …”.
Pollutant
We then look at the pollutants considered in each article. We consider that a pollutant is studied if it is mentioned in the abstract. It is not an exact measure as some articles may mention pollutants without actually studying them but it remains an interesting metric.
Show code
effect_detected %>%
unnest(pollutant) %>%
mutate(pollutant = ifelse(is.na(pollutant), "Pollutant not detected", pollutant)) %>%
ggplot() +
geom_bar(aes(y = fct_rev(fct_infreq(pollutant)), fill = has_effect_phrase)) +
labs(
x = "Number of article mentionning each pollutant",
y = NULL,
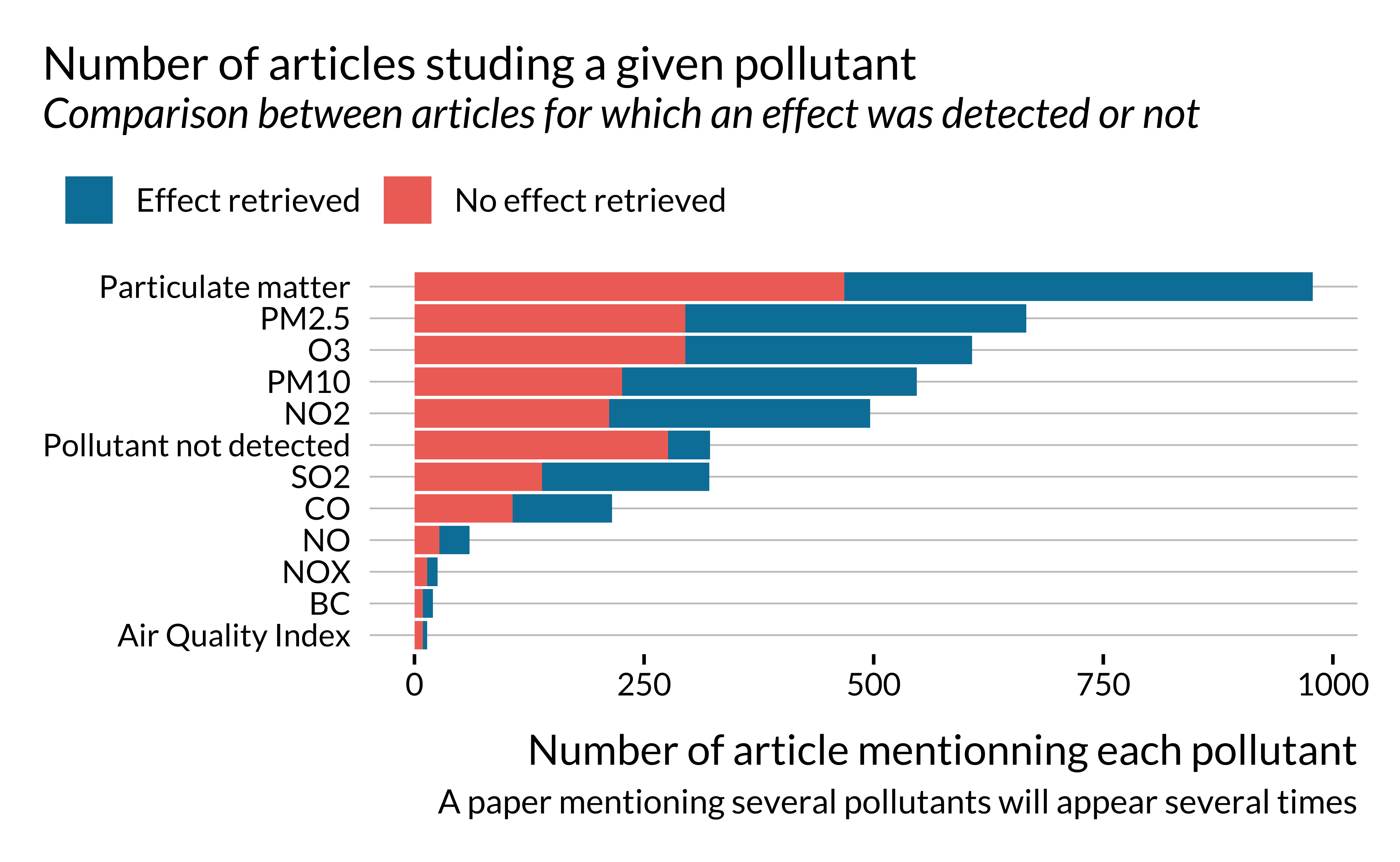
title = "Number of articles studing a given pollutant",
subtitle = "Comparison between articles for which an effect was detected or not",
caption = "A paper mentioning several pollutants will appear several times",
fill = ""
)
First of all, we notice that a large share of papers considered here study particulate matters (PM2.5, PM10 or both).
It seems that, when the number of papers sudying a given pollutant is large, the likelihood of detecting an effect does not seem to vary much with the type of pollutant. Importantly, the proportion of effects retrieved is much lower for articles for which we are not able to detect the type of pollutants studied.
Outcomes
As for pollutants, for some articles, we were able to retrieve studied outcomes depending on the words used in an abstract. We classified them into two categories: mortality and emergency.
Show code
effect_detected %>%
unnest(outcome) %>%
mutate(outcome = ifelse(is.na(outcome), "Outcome not detected", outcome)) %>%
mutate(has_effect = ifelse(has_effect, "Effect detected", "Effect not detected")) %>%
ggplot() +
geom_bar(aes(x = outcome, fill = has_effect), position = "dodge") +
labs(
x = NULL,
y = "Number of articles",
title = "Number of articles studing a given outcome",
subtitle = "Comparison between articles for which an effect was detected or not - articles with unknown outcomes dropped",
fill = ""
) 
Most articles studied here are interested in mortality. The proportion of articles for which an effect is retrieved seems to be larger for papers studying emergency admissions than mortality. There might therefore be some kind of selection issue along this dimension.
Subpopulations
Some articles focus on sub-populations such as infants or elders. When these terms are not mentioned, either the entire population is considered or we are not able to detect the subgroup considered. The number of articles for which a subpopulation is indicated is rather small:
Show code
effect_detected %>%
unnest(subpop) %>%
group_by(doi) %>%
mutate(missing_subpop = is.na(subpop)) %>%
ungroup() %>%
select(doi, missing_subpop) %>%
distinct() %>%
count(missing_subpop = missing_subpop) %>%
mutate(missing_subpop = ifelse(missing_subpop, "No or unknown", "Yes")) %>%
kable(col.names = c("Subpopulation indicated", "Number of articles")) %>%
kable_styling(position = "center")| Subpopulation indicated | Number of articles |
|---|---|
| Yes | 238 |
| No or unknown | 1596 |
Looking more in details into the detection of effects, we get the following pattern:
Show code
effect_detected %>%
unnest(subpop) %>%
mutate(subpop = ifelse(is.na(subpop), "No subpopulation not detected", subpop)) %>%
mutate(has_effect = ifelse(has_effect, "Effect detected", "Effect not detected")) %>%
ggplot() +
geom_bar(aes(x = subpop, fill = has_effect), position = "fill") +
labs(
x = NULL,
y = "Proportion of articles",
title = "Proportion of articles studing a given outcome",
subtitle = "Comparison between articles for which an effect was detected or not - articles with unknown outcomes dropped",
fill = ""
)
There does not seem to be large variations in the proportion of articles for which an effect is detected, depending on whether a subpopulation is studied or not. Yet, this proportion is a slightly larger for elders than infants, itself larger than when when no subpopulation is detected.
Number of observations
We then look at the number of observations, the length of the the study period and the number of cities considered. Importantly, we only retrieve this information for a very limited subset of articles.
Show code
len <- effect_detected %>%
count(Missing = is.na(length_study)) %>%
rename(`Length of the study` = n)
cities <- effect_detected %>%
count(Missing = is.na(n_cities)) %>%
rename(`Number of cities` = n)
obs <- effect_detected %>%
count(Missing = is.na(n_obs)) %>%
rename(`Number of observations` = n)
len %>%
full_join(cities) %>%
full_join(obs) %>%
mutate(Missing = str_to_title(Missing)) %>%
kable() %>%
kable_styling(position = "center")| Missing | Length of the study | Number of cities | Number of observations |
|---|---|---|---|
| False | 630 | 832 | 375 |
| True | 1204 | 1002 | 1459 |
Our analysis is therefore to be taken with caution as there is a critical lack of information for this category.
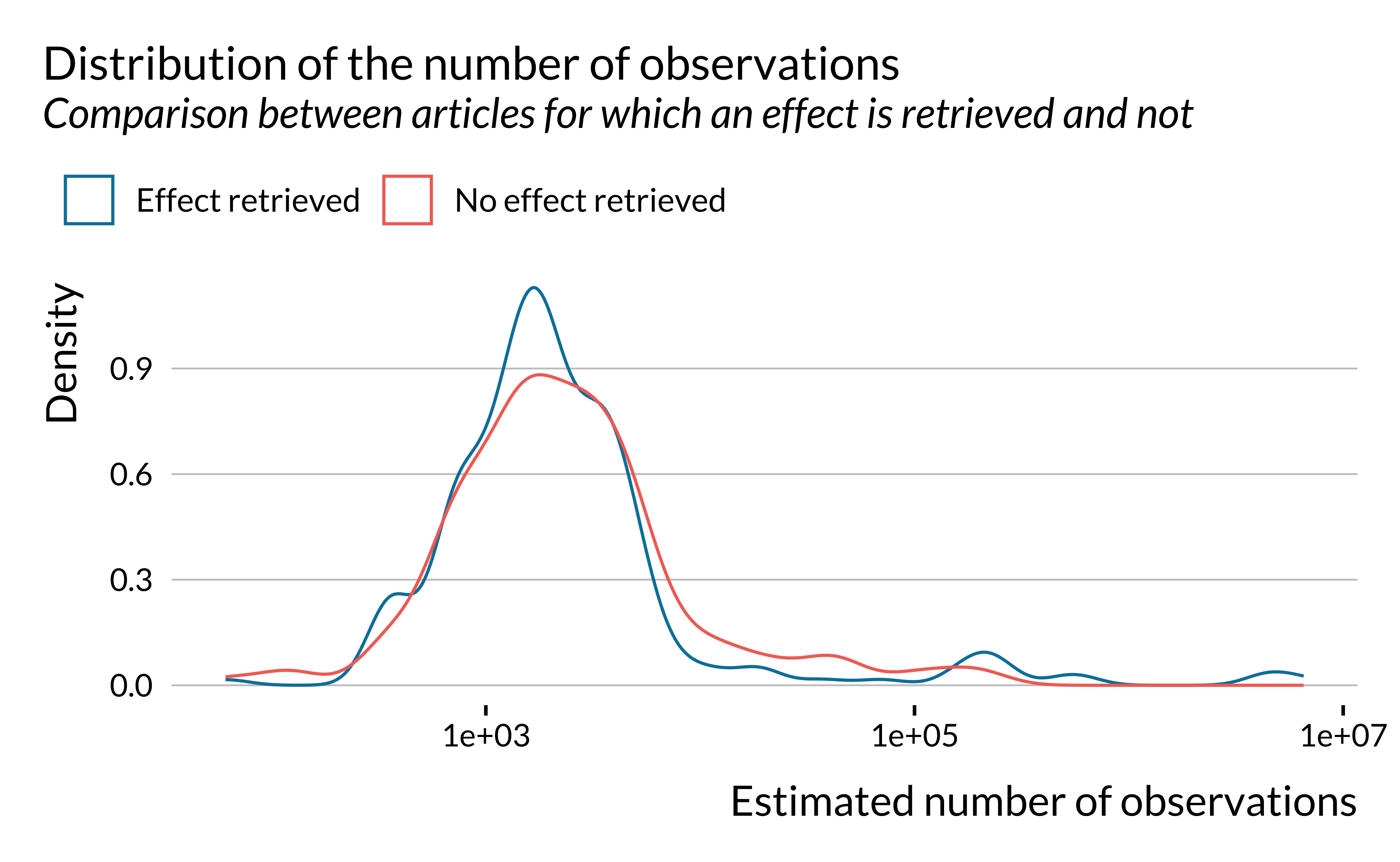
Show code
effect_detected %>%
ggplot() +
geom_density(aes(x = n_obs, color = has_effect_phrase), fill = NA) +
labs(
title = "Distribution of the number of observations",
subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated number of observations",
y = "Density",
color = ""
) +
scale_x_log10() 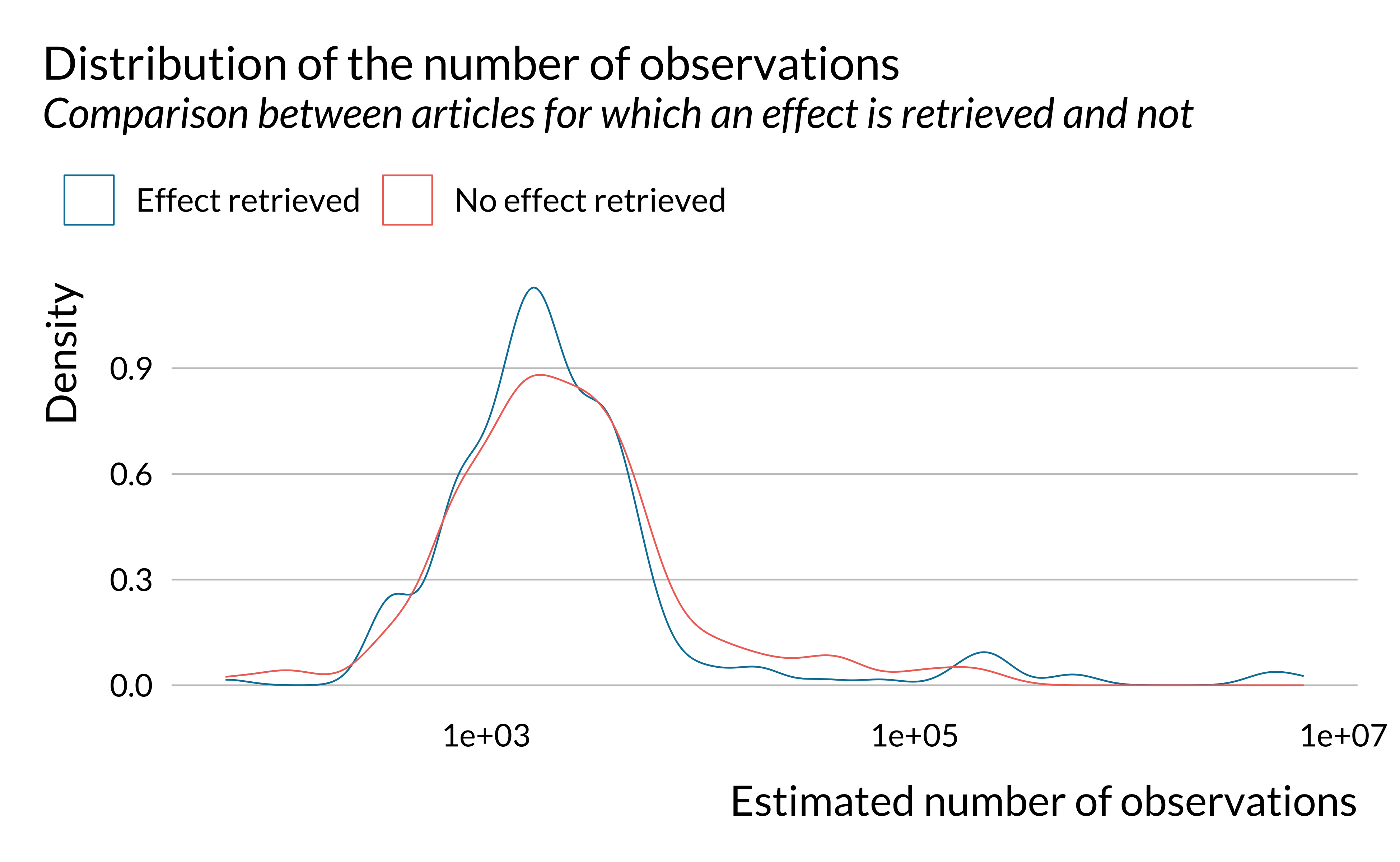
Show code
effect_detected %>%
ggplot() +
geom_density(aes(x = length_study, color = has_effect_phrase), fill = NA) +
labs(
title = "Distribution of the length of the study",
subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated length of the study (in days)",
y = "Density",
color = ""
) +
scale_x_log10() 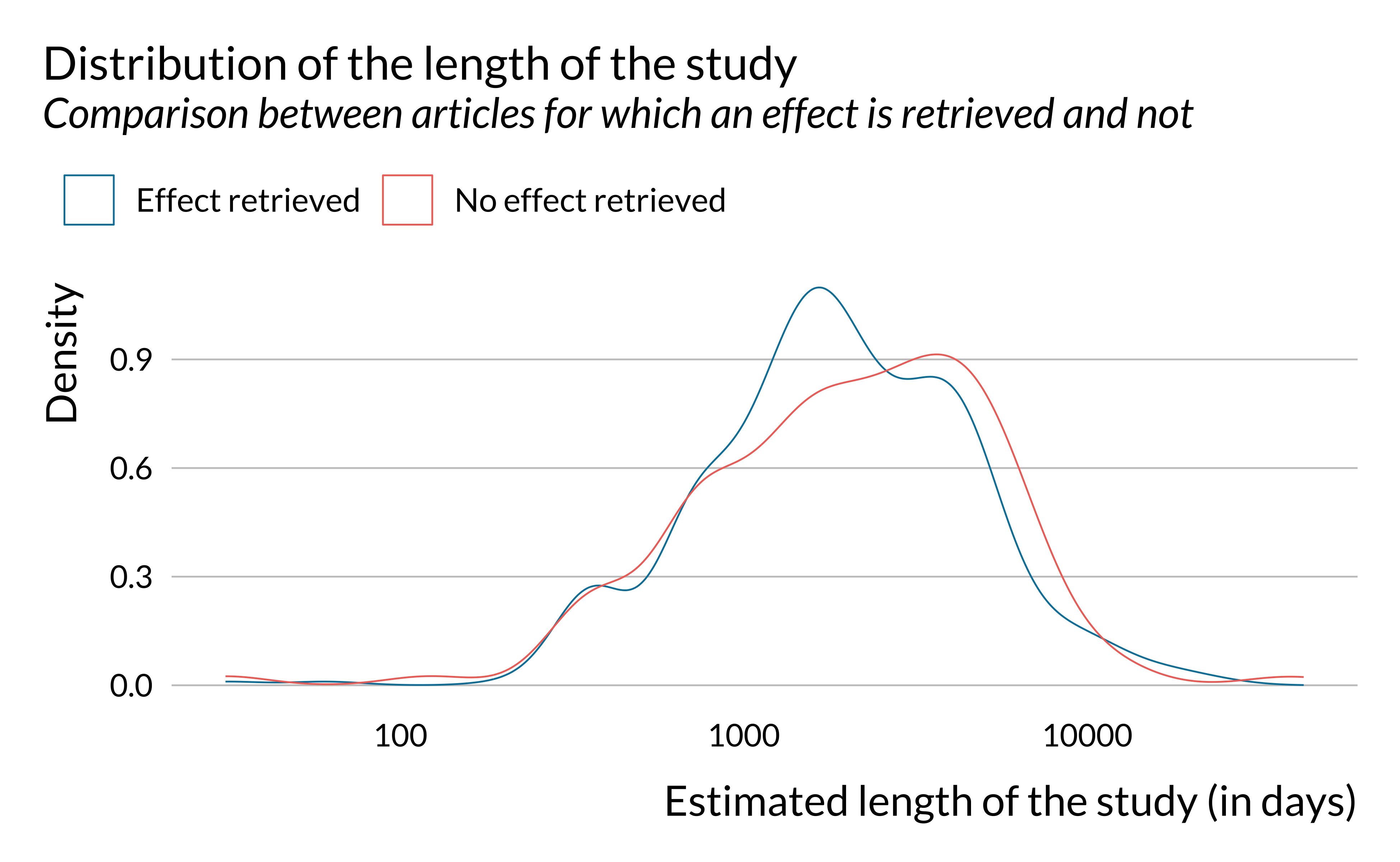
Show code
effect_detected %>%
ggplot() +
geom_density(aes(x = n_cities, color = has_effect_phrase), fill = NA) +
labs(
title = "Distribution of the number of cities in the study",
subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated number of cities",
y = "Density",
color = ""
) +
scale_x_log10()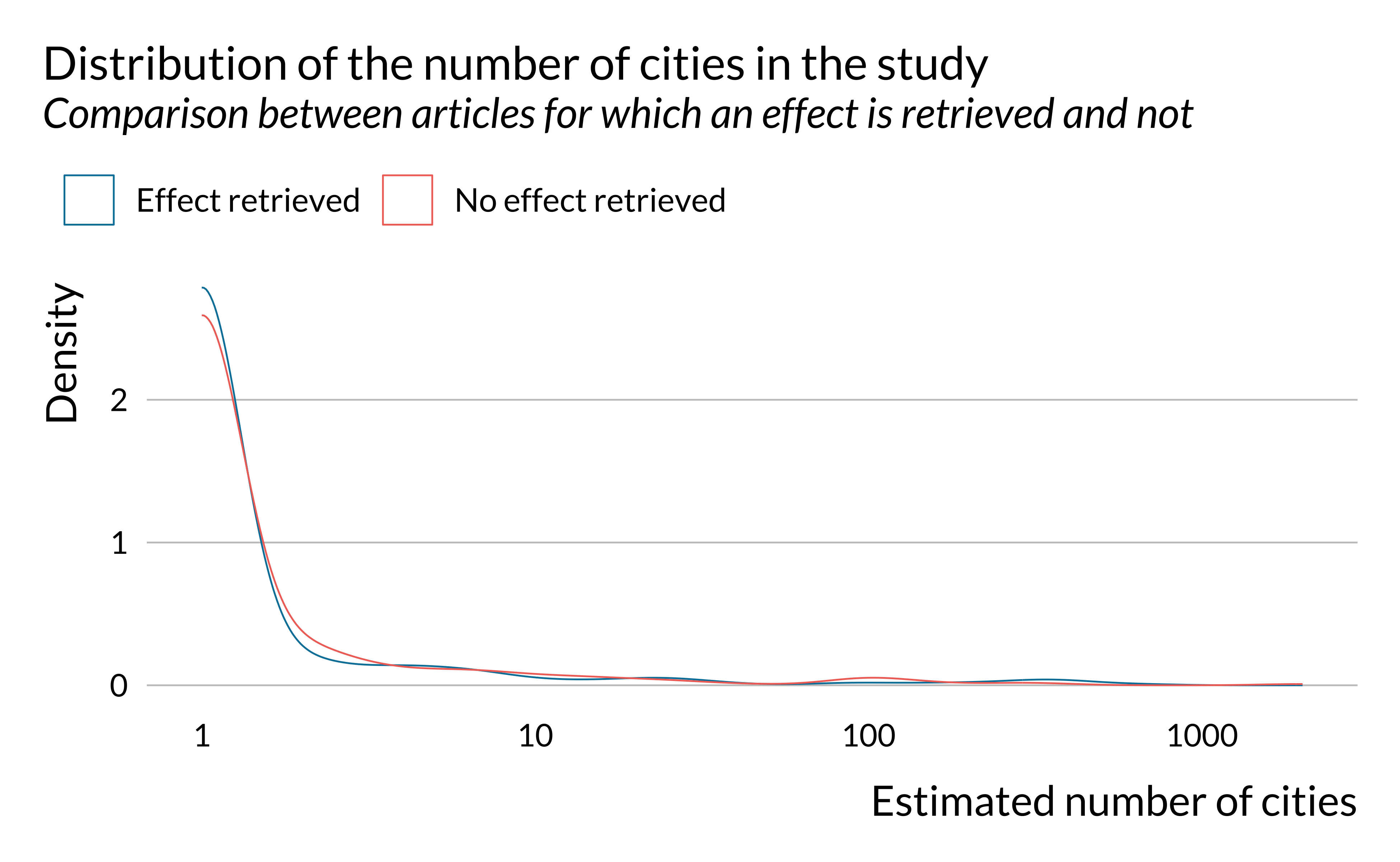
We notice that there are large variations in the number of observations in the studies considered. However, there does not seem to be large differences along this dimension on whether an effect is retrieved or not. There seems however to be more studies around 1000 observations and less between 10,000 and 100,000 in articles for which an effect is retrieved. This is explained by the fact effects are retrieved more for studies with rather limited study period (around 3 years).
Summary
The articles for which an effect was detected, unsurprisingly, seem to be slightly different from those for which we did not detect one, based on our quick qualitative analysis. Yet, there does not seem to be important divides along the dimensions studied.
We can thus now dig further into the analysis of the estimates retrieved.
Analysis of the Effects
In this section, we briefly analyze the effects retrieved, their statistical significance and their precision.
Significance
First, we notice that most of the effects retrieved here are significant (at the usual 5% threshold).
Show code
estimates_stats <- estimates %>%
filter(valid) %>%
select(-valid) %>%
mutate(
signal_noise = abs(effect/(up_CI - low_CI)),
se = abs(up_CI - low_CI)/(2*1.96),
t_score = abs(effect)/se,
significant = abs(t_score)>=1.96
)
estimates_stats %>%
count(significant) %>%
mutate(prop = n/sum(n)) %>%
mutate(significant = ifelse(significant, "Yes", "No")) %>%
kable(col.names = c("Significant", "Number of effects", "Proportion")) %>%
kable_styling(position = "center")| Significant | Number of effects | Proportion |
|---|---|---|
| No | 173 | 0.0802784 |
| Yes | 1982 | 0.9197216 |
Researchers mention their key findings in the abstract and therefore probably do not report in their abstracts non statistically significant estimates for which the null hypothesis of no effect cannot be rejected. Only a very small proportion of articles do not report any statistically significant estimates in their abstract:
Show code
estimates_stats %>%
group_by(doi) %>%
mutate(has_significant = (sum(significant) > 0) ) %>%
ungroup() %>%
select(has_significant, doi) %>%
distinct() %>%
count(has_significant) %>%
mutate(prop = n/sum(n)) %>%
mutate(has_significant = ifelse(has_significant, "Yes", "No")) %>%
kable(col.names = c("At least one significant estimate", "Number of articles", "Proportion")) %>%
kable_styling(position = "center")| At least one significant estimate | Number of articles | Proportion |
|---|---|---|
| No | 10 | 0.0149701 |
| Yes | 658 | 0.9850299 |
t-Statistics
We then look into the distribution of the t-scores.
Show code
distrib_t_stat_epi <- estimates_stats %>%
filter(t_score < 10) %>%
ggplot() +
geom_histogram(aes(x = t_score), bins = 50, colour = "white") +
geom_vline(xintercept = 1.96, linewidth = 1.2, linetype = "dashed") +
labs(
x = "t-stat",
y = "Count"
)
distrib_t_stat_epi +
labs(
title = "Distribution of the t-statistics of estimates of the literature",
subtitle = "Only considering observations with a t-stat lower than 10",
caption = "The vertical line represents the usual 1.96 threshold"
) 
Show code
# save the graph
ggsave(
distrib_t_stat_epi,
filename = here::here(
"images",
"std_lit_analysis",
"distrib_t_stat_epi.pdf"
),
width = 18,
height = 10,
units = "cm"
# device = cairo_pdf
)There seems to be some sort of bunching for t-scores above 1.96. In this analysis, we only consider estimates reported in the abstracts. Authors may only report significant estimates in their abstracts even though they also report non significant estimates in the body of the article. This might explain this bunching. We need to investigate this further in order to understand whether this bunching is evidence of publication bias. To do so, we could reproduce the present analysis but analyze the full texts and not only on the abstracts. Other techniques could be used to analyze reporting bias but are not available to us, considering the lack on information we have access to using this automated method.
Signal to noise ratio
We then plot the distribution of the signal to noise ratio, ie the ratio of the point estimate and the width of the confidence interval.
Show code
estimates_stats %>%
filter(signal_noise < 4) %>%
ggplot() +
geom_histogram(aes(x = signal_noise), bins = 50, colour = "white") +
geom_vline(xintercept = 0.5, linewidth = 1.2, linetype = "solid") +
labs(
title = "Distribution of the signal to noise ration in estimates of the literature",
subtitle = "Only considering observations with a signal to noise ration lower than 4",
caption = "The vertical line represents the usual 0.5 threshold",
x = "Signal to noise ration",
y = "Count"
) 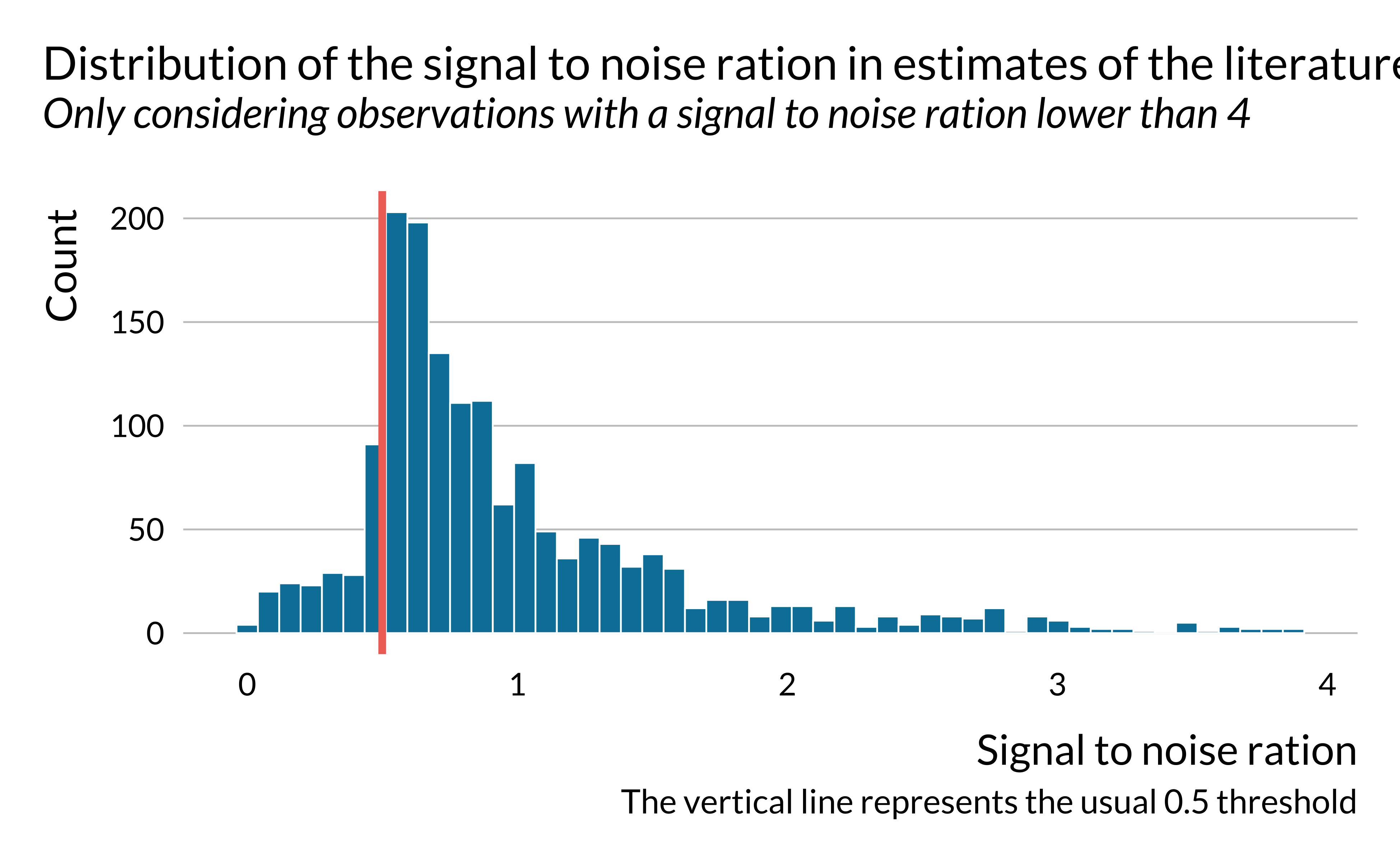
The graph is of course analogous to the previous one. It however underlines that in a large share of the studies, the magnitude of the noise is larger than the magnitude of the effect. We then look into the distribution of the signal to noise ratio in more details.
Show code
# A tibble: 11 × 2
perc snr
<dbl> <dbl>
1 0 0
2 0.1 0.513
3 0.2 0.600
4 0.3 0.688
5 0.4 0.826
6 0.5 1.02
7 0.6 1.38
8 0.7 2.46
9 0.8 47.6
10 0.9 70.6
11 1 33167. Show code
| Signal to noise ratio | Percentage of estimates with a lower signal to noise ratio |
|---|---|
| 0% | 0.00 |
| 10% | 0.51 |
| 20% | 0.60 |
| 30% | 0.69 |
| 40% | 0.83 |
| 50% | 1.02 |
| 60% | 1.38 |
| 70% | 2.46 |
| 80% | 47.57 |
| 90% | 70.65 |
| 100% | 33166.67 |
We notice that for about 55% of the estimates considered here, the magnitude of the noise is more important than those of the signal. This is particularly concerning.
Retrospective Power analysis
We then turn to the power analysis. The objective is to evaluate the power, exaggeration and type S errors for each estimate.
To compute these values, we would need to know the true effect size. Yet, true effects are of course unknown. One solution could be to use estimates from the literature and meta-analyses as best guesses for these true values. Yet, in the setting of this automated literature review, detecting what is exactly measured in each analysis is particularly challenging since there is no standardized way of reporting the results beyond mentioning confidence intervals. One study may for instance claim that a 10 \(\mu g/m^{3}\) increase in PM2.5 concentration is associated with an increase of x% in hospital admissions over the course of a day while another study may state that a 2% increase in ozone concentration increases the number of deaths by 3 over a month. Fortunately, for each estimate retrieved, even though we do not know what is measured, we can evaluate the precision with which it is estimated.
To circumvent the fact that we do not know the actual effect size, we follow a strategy suggested by Gelman and Carlin (2014). We consider a range of potential “true” effect sizes and run a sensitivity analysis. We investigate what would be the power, exaggeration and type S error if the true effect was only a fraction of the measured effect. This enables us to assess whether the design of the study would be good enough to detect a smaller effect. If assuming that the true effect is half of the measured effect yields a power of 30%, there is probably a major issue with the design of this study. With this design, this (non zero) effect would only be detected 30% of the time.
Of course, there is no reason to think a priori that a given effect would be overestimated. The values for power, exaggeration and type S errors are therefore only informative.
To carry out the analysis, we use the package retrodesign which computes post analysis design calculations (power, exaggeration and type S errors). We run the function retro_desing() for several effect sizes.
In a first part, we investigate whether the literature might be subject to design issues. We analyze the distribution of power, exaggeration and type S errors in the whole set of abstracts, how they evolve jointly or along several variables such as the size of the true effect. We find clear evidence of heterogeneity across articles. Some of them seem to present robust designs while others seem much more problematic, yielding low power and high rates of type M error, even for large hypothesized true effect sizes.
We then compute and plot power and exaggeration curves. They represent the statistical power and exaggeration ratio of each study against hypothetical true effect sizes defined as a fraction of the observed estimates.
Show code
data_retrodesign_fraction <- estimates_stats %>%
filter(abs(t_score) >= 1.96) %>%
mutate(id = 1:nrow(.)) %>%
crossing(percentage = seq(from = 30, to = 100, by = 1) / 100) %>%
mutate(hypothetical_effect_size = percentage * effect) |>
mutate(
retro = map2(hypothetical_effect_size, se,
\(x, y) retro_design_closed_form(x, y))
#retro_design returns a list with power, type_s, type_m
) |>
unnest_wider(retro) |>
mutate(power = power * 100, type_s = type_s * 100)
# compute median values of metrics for the entire literature
data_retrodesign_fraction_median <- data_retrodesign_fraction %>%
pivot_longer(
cols = c(power, type_m, type_s),
names_to = "metric",
values_to = "value"
) %>%
mutate(
metric = case_when(
metric == "power" ~ "Statistical Power (%)",
metric == "type_m" ~ "Exaggeration Ratio",
metric == "type_s" ~ "Type S Error (%)"
)
) %>%
group_by(metric, percentage) %>%
summarise(median_value = median(value))Show code
# make the graph
graph_retrodesign_epi <- data_retrodesign_fraction %>%
pivot_longer(
cols = c(power, type_m, type_s),
names_to = "metric",
values_to = "value"
) %>%
mutate(
metric = case_when(
metric == "power" ~ "Statistical Power (%)",
metric == "type_m" ~ "Exaggeration Ratio",
metric == "type_s" ~ "Type S Error (%)"
)
) %>%
mutate(value = ifelse(metric == "Exaggeration Ratio" & value>3, NA, value)) %>%
filter(metric != "Type S Error (%)") %>%
ggplot(., aes(
x = percentage * 100,
y = value,
group = interaction(id)
)) +
geom_line(colour = "#dee2e6", alpha = 0.1) +
geom_line(
data = data_retrodesign_fraction_median %>% filter(metric != "Type S Error (%)"),
aes(
x = percentage * 100,
y = median_value,
group = "l"
),
colour = "#0081a7",
linewidth = 1.5
) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 5)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 5)) +
facet_wrap( ~ fct_rev(metric), scales = "free_y") +
xlab("True Effect Size as Fraction of Observed Estimate (%)") + ylab(NULL) +
theme(panel.grid.major.y = element_blank(),
# axis ticks
axis.ticks.x = element_line(size = 0.5, color = "black"),
axis.ticks.y = element_line(size = 0.5, color = "black"),
axis.ticks.length = unit(0.15, "cm"))
# display the graph
graph_retrodesign_epi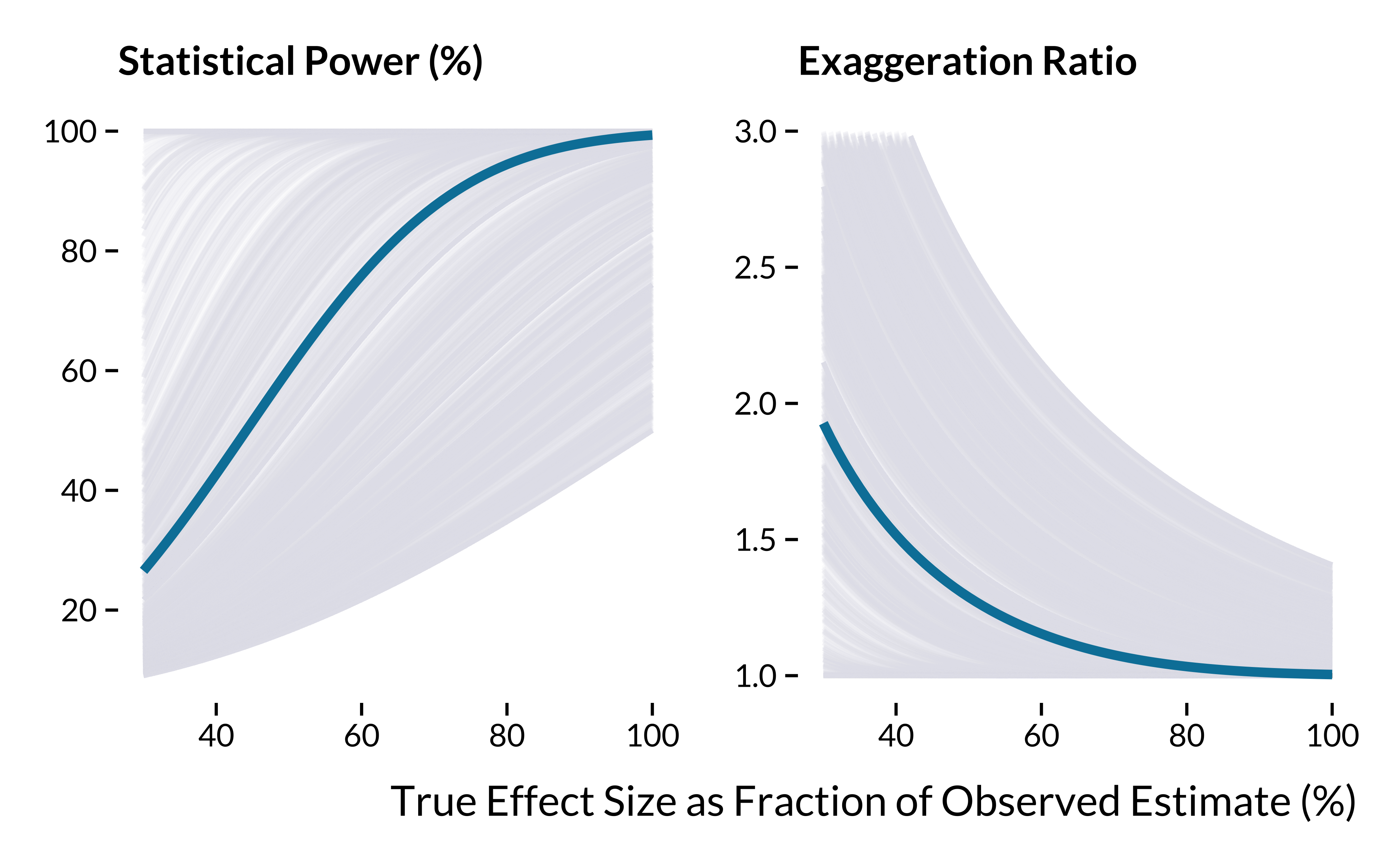
Show code
# save the graph
ggsave(
graph_retrodesign_epi,
filename = here::here(
"images",
"std_lit_analysis",
"graph_retrodesign_epi.pdf"
),
width = 18,
height = 10,
units = "cm"
# device = cairo_pdf
)The summary statistics when the true effect is half of the estimates are:
Show code
# summary statistics
data_retrodesign_fraction %>%
pivot_longer(
cols = c(power, type_m, type_s),
names_to = "metric",
values_to = "value"
) %>%
mutate(
metric = case_when(
metric == "power" ~ "Statistical Power (%)",
metric == "type_m" ~ "Exaggeration Ratio",
metric == "type_s" ~ "Type S Error (%)"
)
) %>%
filter(percentage == 0.5) %>%
group_by(metric) %>%
summarise(
"Min" = min(value, na.rm = TRUE),
"First Quartile" = quantile(value, na.rm = TRUE)[2],
"Mean" = mean(value, na.rm = TRUE),
"Median" = median(value, na.rm = TRUE),
"Third Quartile" = quantile(value, na.rm = TRUE)[4],
"Maximum" = max(value, na.rm = TRUE)
) %>%
mutate_at(vars(-metric), ~ round(., 1)) %>%
rename(Metric = metric) %>%
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")| Metric | Min | First Quartile | Mean | Median | Third Quartile | Maximum |
|---|---|---|---|---|---|---|
| Exaggeration Ratio | 1.0 | 1.0 | 1.5 | 1.3 | 1.9 | 2.5 |
| Statistical Power (%) | 16.5 | 28.1 | 62.6 | 60.3 | 100.0 | 100.0 |
| Type S Error (%) | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 | 1.0 |
Summary
If the true effects of studies were equal to half of the estimates, half of the literature would overestimate effect sizes by a factor of at least 1.5. A quarter of the literature would overestimate the true effect sizes by 1.9. We need to investigate further into the sources of this heterogeneity.
Analysis of the sources of heterogeneity
We then investigate potential sources of heterogeneity. We start by building graphs and then turn to a more synthetic regression analysis.
To simplify and clarify our analysis, we consider that an estimate has low power if its computed power is lower than 80% if the true effect is half of the measured effect. These numbers are arbitrary. 80% is the threshold usually used in power analyses and half is purely arbitrary and could be changed easily in a robustness check. Following this criterion, the number and proportion of estimates with low power is as follows:
Show code
articles_low_adequate <- data_retrodesign_fraction %>%
filter(percentage == 0.5) %>%
mutate(
low_power = (power <= 80),
low_power_phrase = ifelse(low_power, "Low power", "Adequate power")
) %>%
left_join(abstracts_and_metadata, by = "doi")
articles_low_adequate %>%
count(low_power_phrase) %>%
mutate(prop = round(n/sum(n)*100, 0)) %>%
kable(col.names = c("Power", "Number of estimates", "Proportion")) %>%
kable_styling(position = "center")| Power | Number of estimates | Proportion |
|---|---|---|
| Adequate power | 841 | 42 |
| Low power | 1141 | 58 |
Based this criterion, the number of studies with low power is concernedly high.
Such articles are also associated with large exaggeration:
Show code
articles_low_adequate %>%
group_by(low_power_phrase) %>%
summarise(
mean_type_m = mean(type_m),
median_type_m = median(type_m)
) %>%
mutate_at(vars(mean_type_m, median_type_m), ~ round(., 2)) %>%
kable(col.names = c("Power", "Mean exaggeration", "Median exaggeration")) %>%
kable_styling(position = "center")| Power | Mean exaggeration | Median exaggeration |
|---|---|---|
| Adequate power | 1.01 | 1.00 |
| Low power | 1.79 | 1.77 |
We investigate the particularities of articles with seemingly low power. We basically reproduce the same analyses as the ones used to compare articles for which we retrieved an effect or not.
Publication date
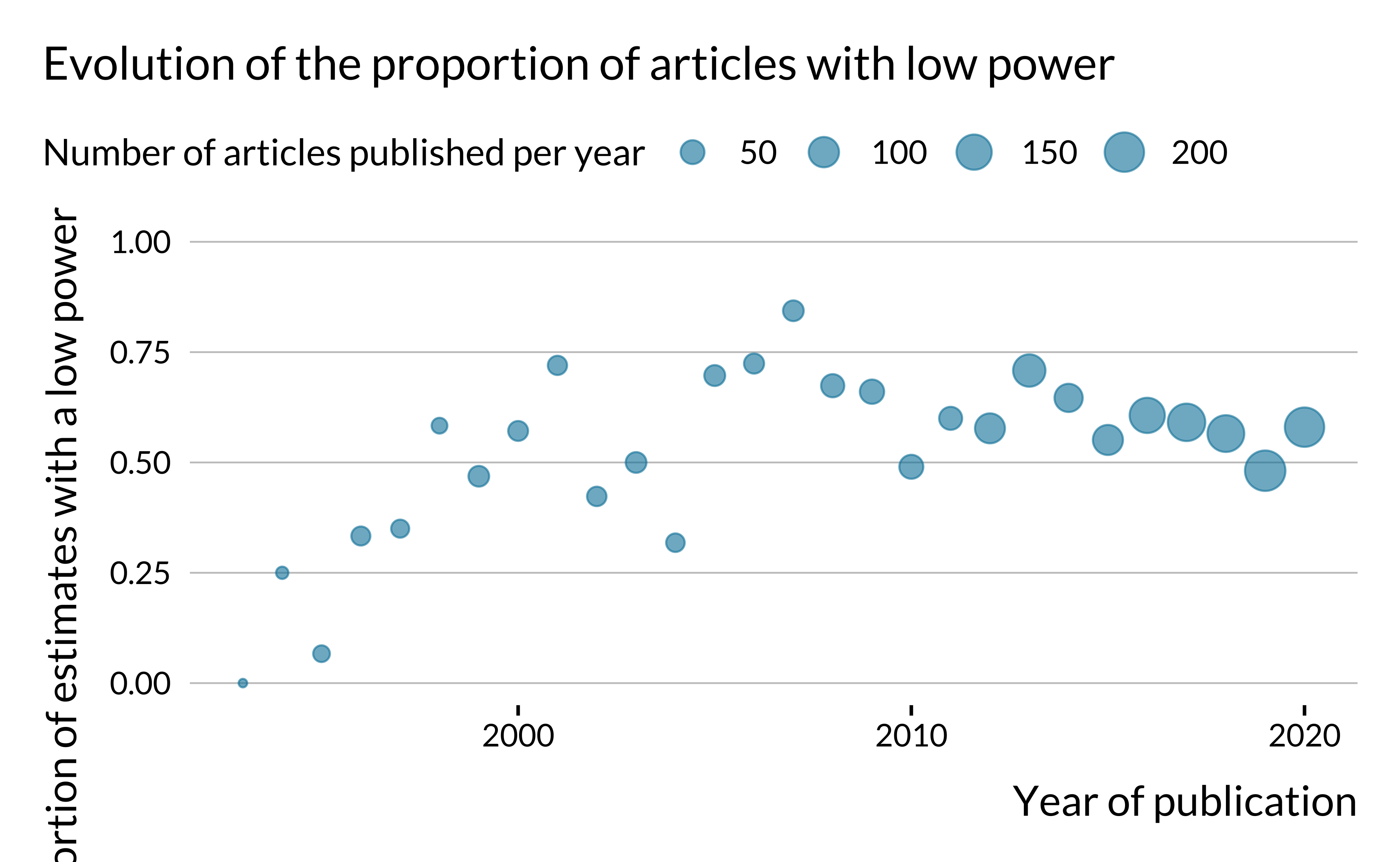
First, we look into the evolution of the proportion of articles with low power with publication dates.
Show code
articles_low_adequate %>%
group_by(year = year(pub_date)) %>%
summarise(
n = n(),
prop_low_power = sum(low_power)/n(),
.groups = "drop"
) %>%
# filter(low_power) %>%
filter(year <= 2020) %>%
ggplot() +
geom_point(aes(x = year, y = prop_low_power, size = n), alpha = 0.6) +
# geom_line(linetype = "dashed", size = 0.2) +
# geom_smooth(color = "#8D0422", fill = "#8D0422") +
ylim(c(0,1)) +
labs(
title = "Evolution of the proportion of articles with low power",
size = "Number of articles published per year",
x = "Year of publication",
y = "Proportion of estimates with a low power"
)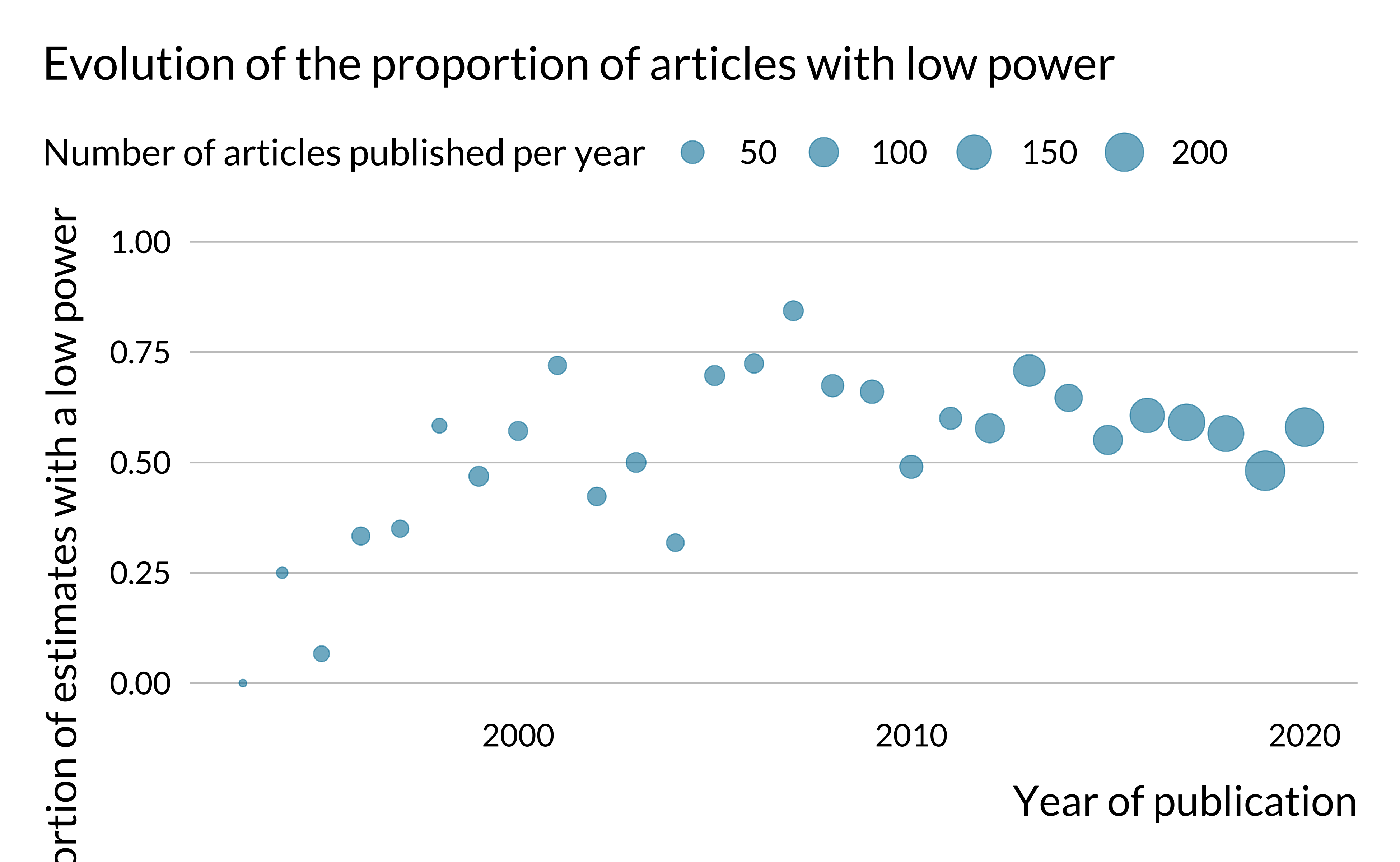
The proportion of articles with low power does not seem to have drastically evolved after the 1990s. One may have expected that this proportion would have decreased in time as researchers have access to more and more data, computational power and as estimation methods improve.
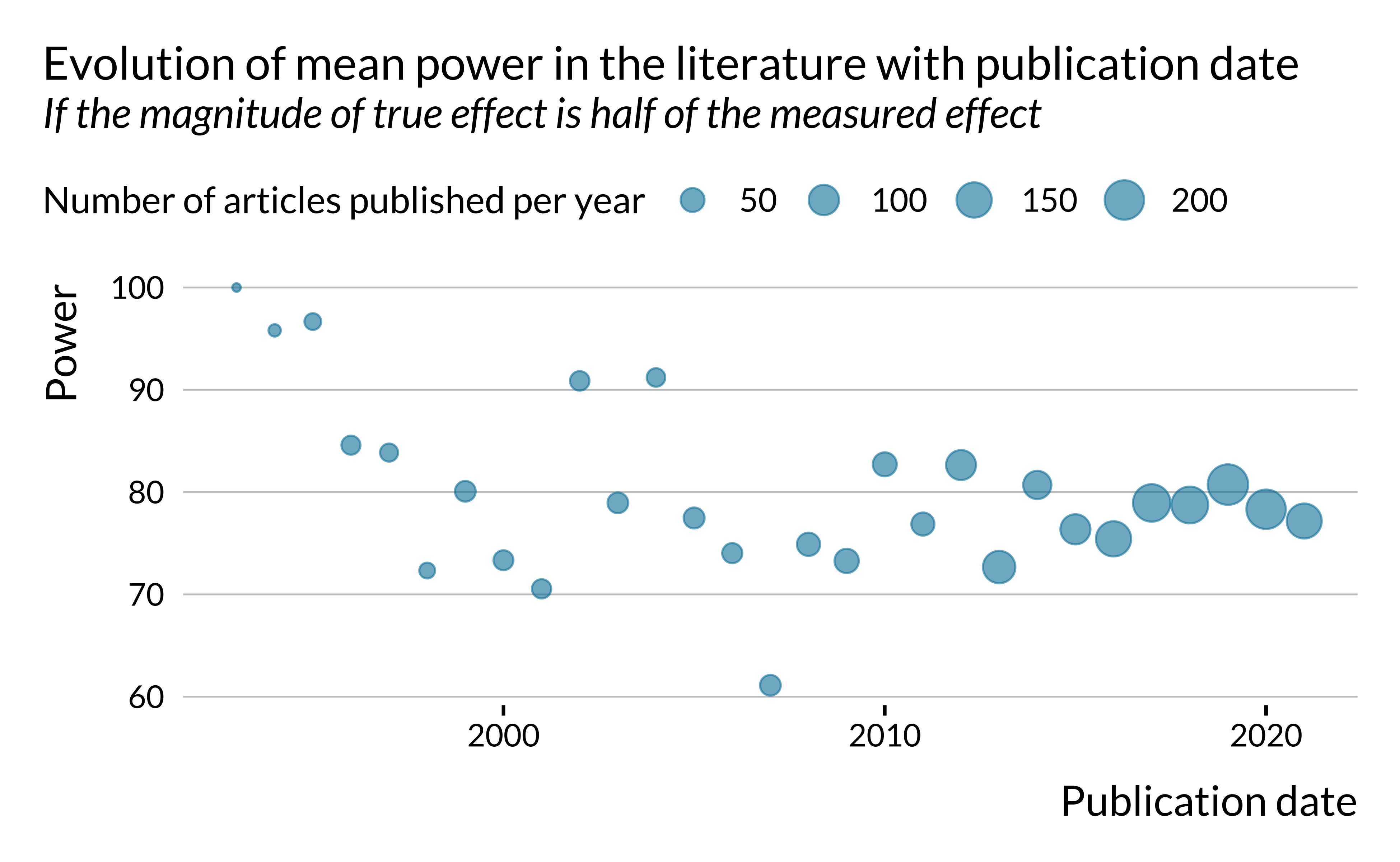
We can also look more generally at how power, exaggeration and type S error evolved in time.
Show code
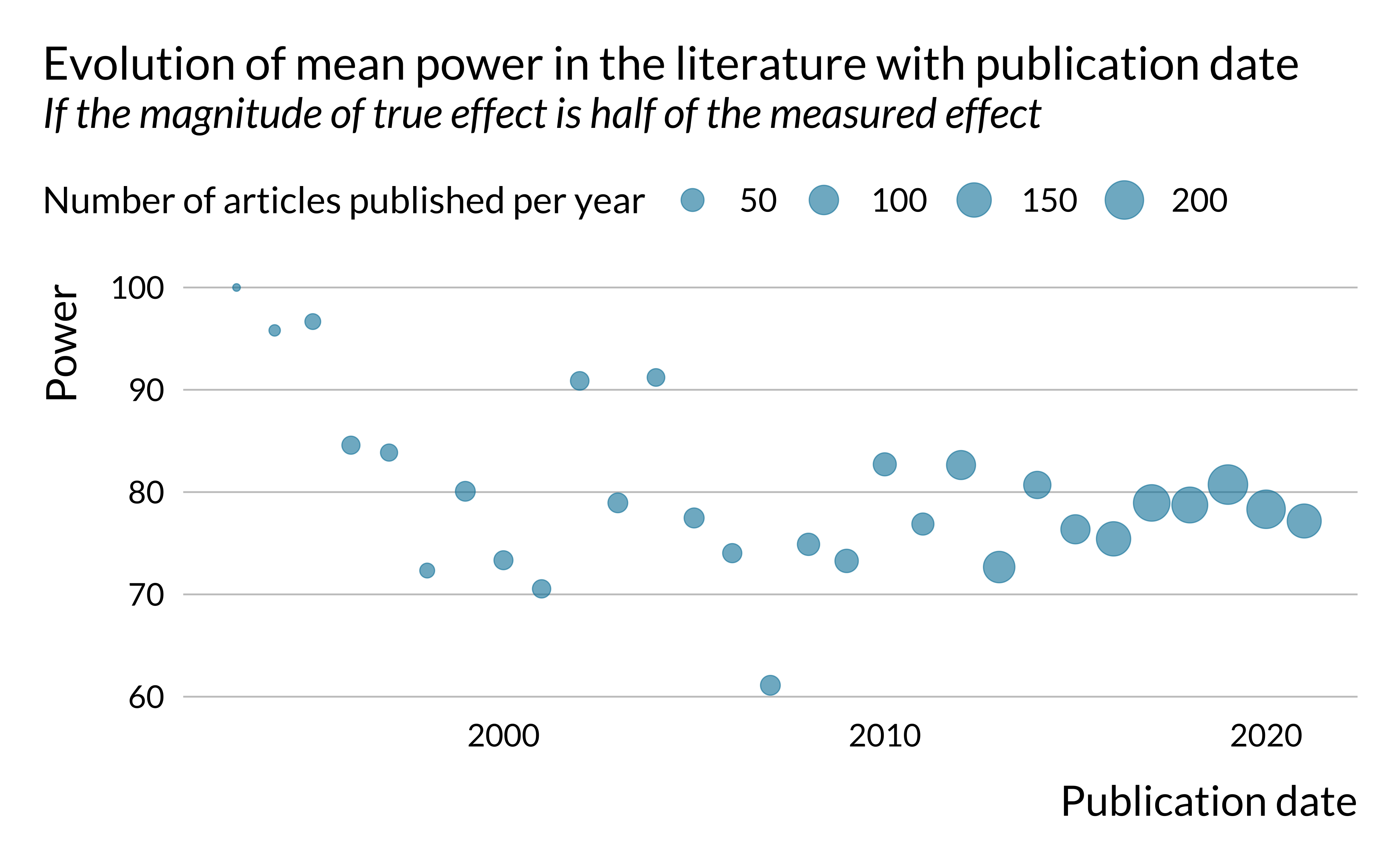
retro_analysis_pubdate <- data_retrodesign_fraction %>%
left_join(abstracts_and_metadata %>% select(doi, pub_date), by = "doi")
retro_analysis_pubdate %>%
filter(percentage == 0.75) %>%
group_by(year = year(pub_date), percentage) %>%
summarise(
power = mean(power, na.rm = TRUE),
n = n(),
groups = ".drop"
) %>%
ggplot() +
geom_point(aes(x = year, y = power, size = n), alpha = 0.6) +
# geom_smooth(size = 0.3) +
# facet_wrap(~ prop_true_effect_phrase) +
labs(
title = "Evolution of mean power in the literature with publication date",
subtitle = "If the magnitude of true effect is half of the measured effect",
size = "Number of articles published per year",
x = "Publication date",
y = "Power"
)
Show code
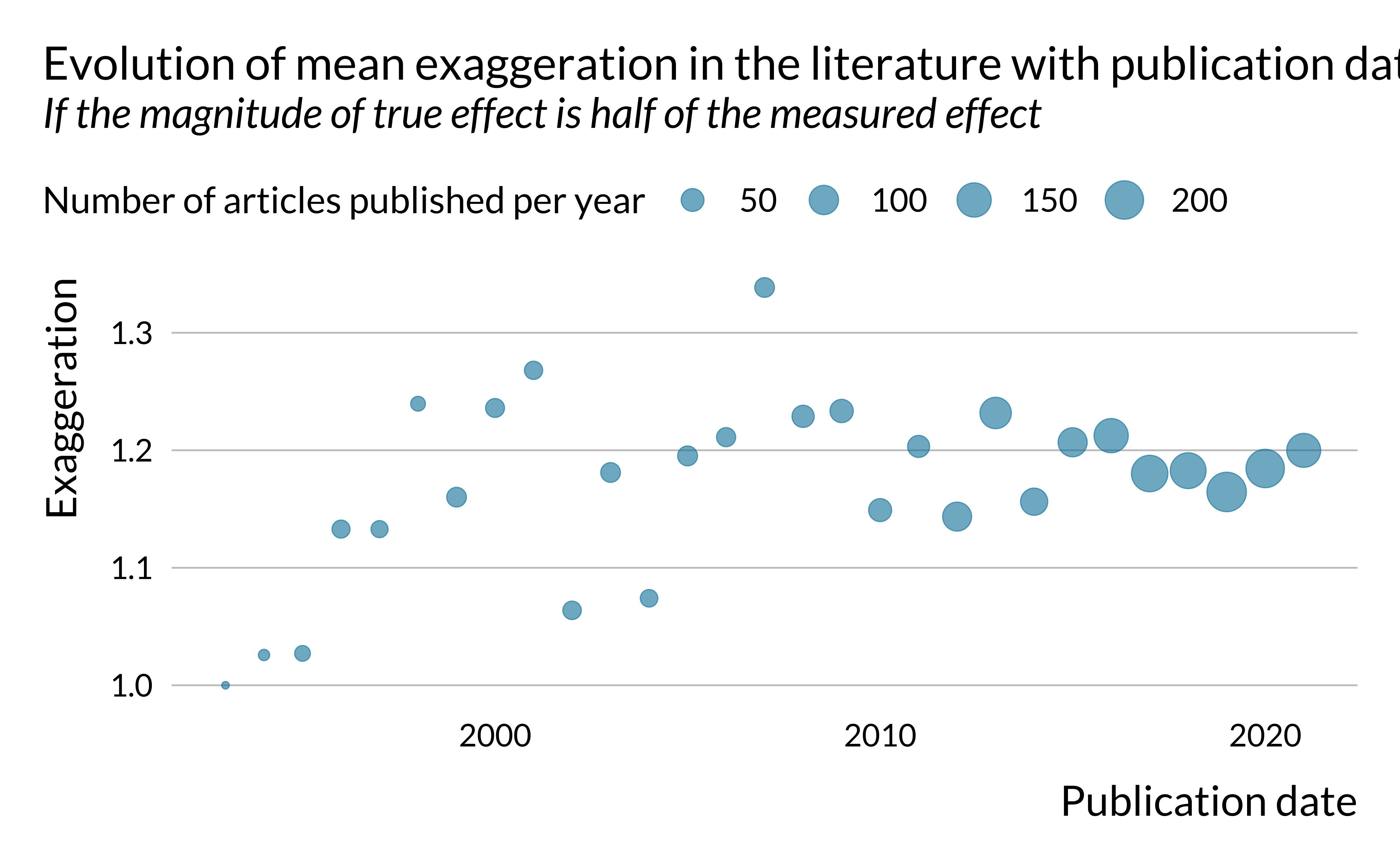
retro_analysis_pubdate %>%
filter(percentage == 0.75) %>%
group_by(year = year(pub_date), percentage) %>%
summarise(
type_m = mean(type_m, na.rm = TRUE),
n = n(),
groups = ".drop"
) %>%
ggplot() +
geom_point(aes(x = year, y = type_m, size = n), alpha = 0.6) +
# geom_smooth(size = 0.3) +
# geom_smooth(size = 0.3, formula = y ~ x + I(x^2)) +
# facet_wrap(~ prop_true_effect_phrase) +
labs(
title = "Evolution of mean exaggeration in the literature with publication date",
subtitle = "If the magnitude of true effect is half of the measured effect",
size = "Number of articles published per year",
x = "Publication date",
y = "Exaggeration"
)
Show code
retro_analysis_pubdate %>%
filter(percentage == 0.75) %>%
group_by(year = year(pub_date), percentage) %>%
summarise(
type_s = mean(type_s, na.rm = TRUE),
n = n(),
groups = ".drop"
) %>%
ggplot(aes(x = year, y = type_s, size = n)) +
geom_point(alpha = 0.6) +
# geom_smooth(size = 0.3) +
labs(
title = "Evolution of mean type S error in the literature with publication date",
subtitle = "If the magnitude of true effect is half of the measured effect",
size = "Number of articles published per year",
x = "Publication date",
y = "Type S error rate"
)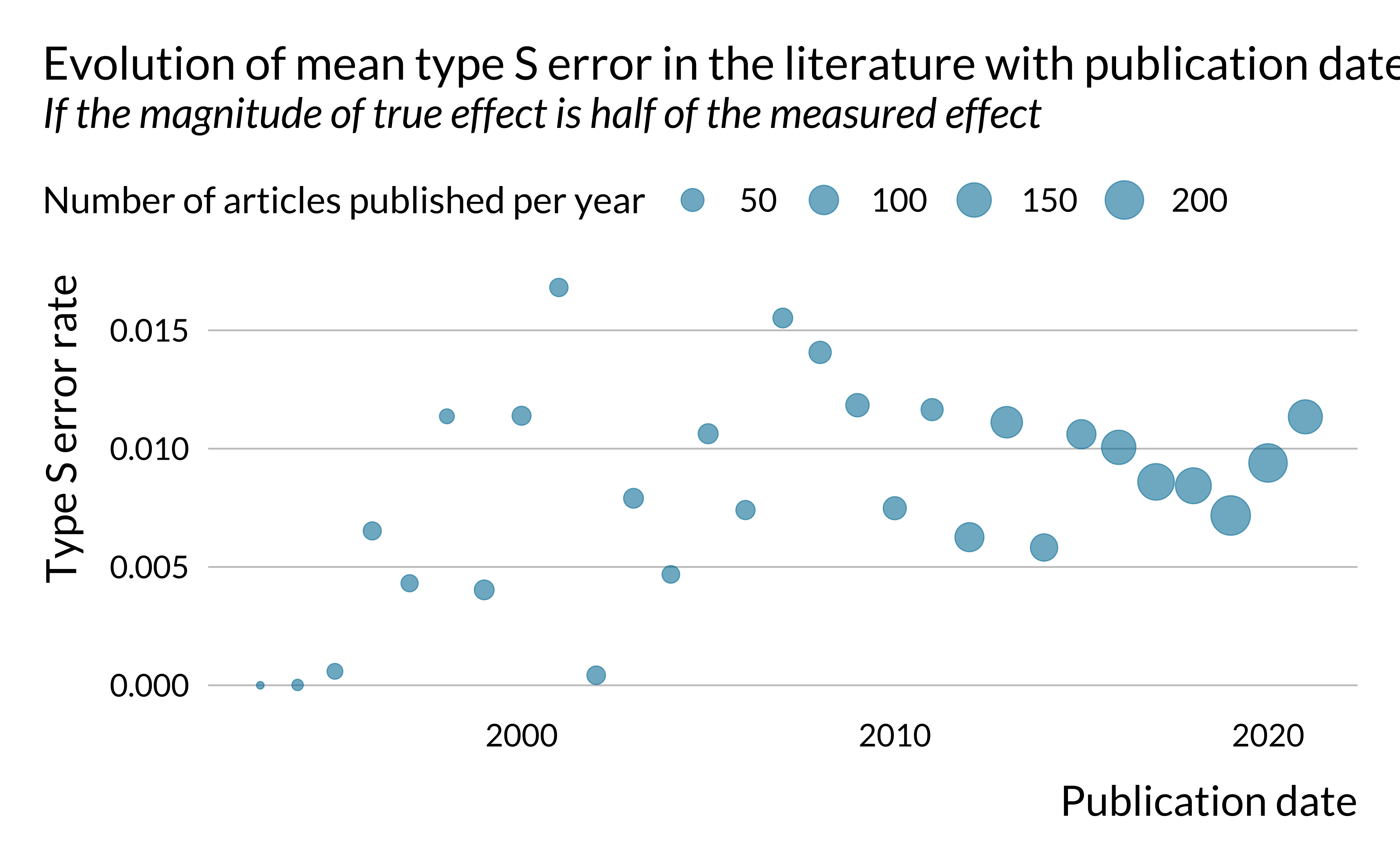
There does not seem to be a clear trend in the evolution of power and type S error. However, exaggeration seems to increase slightly in time. This is rather concerning. One may potentially explain that by the fact that the literature is chasing smaller and smaller effects, leading to more exaggeration. This hypothesis is however difficult to verify since the effects we retrieved are not standardized, as mentioned previously.
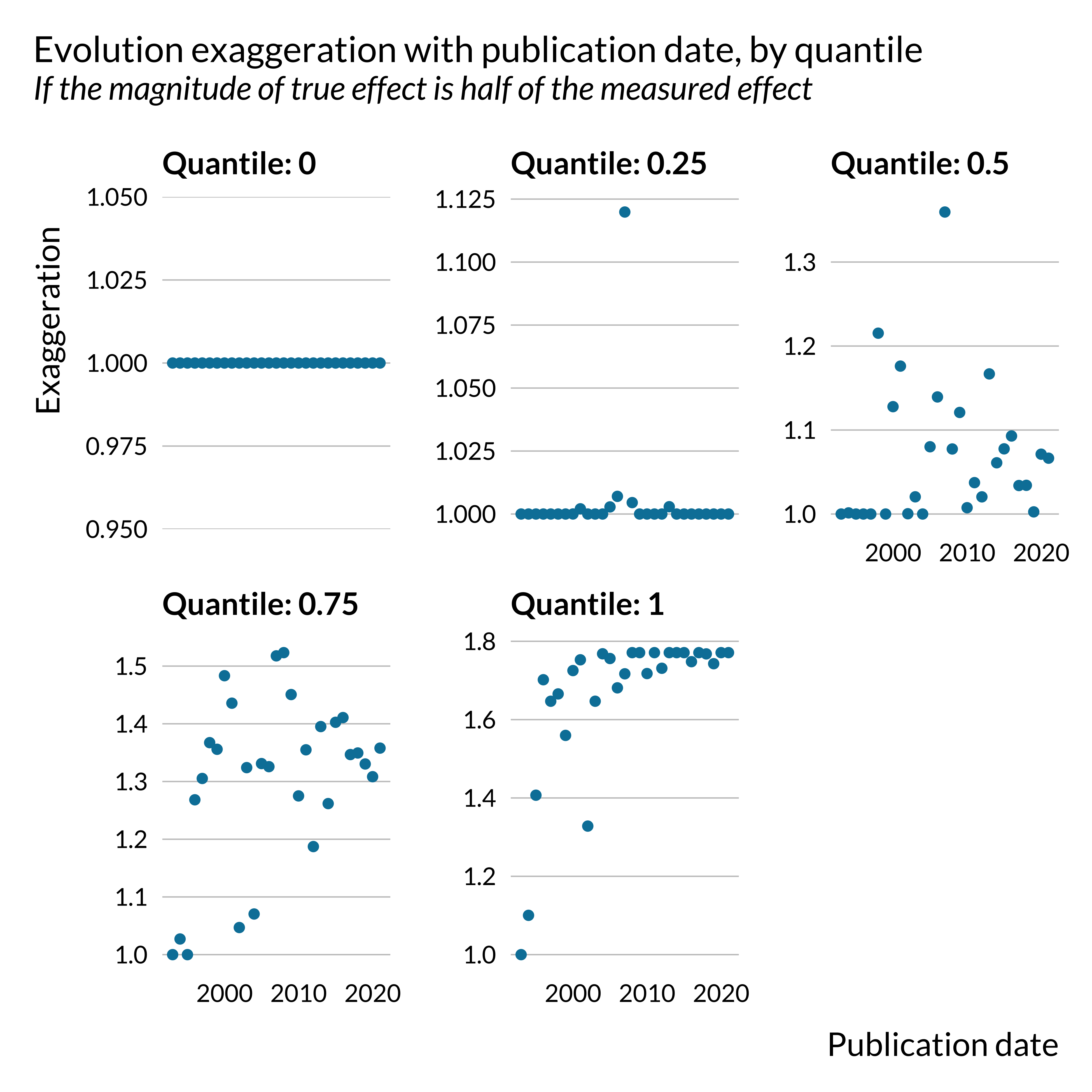
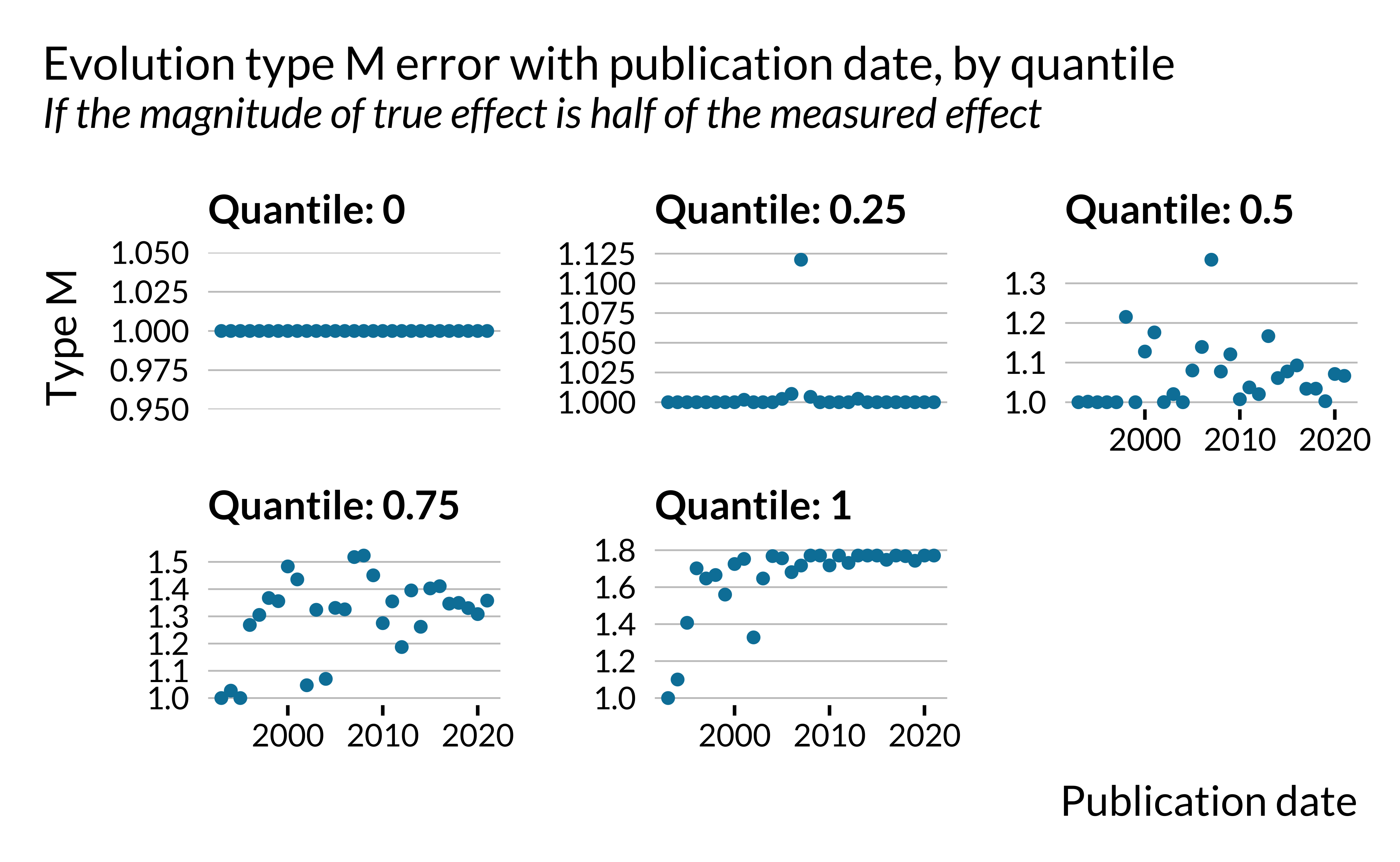
Carrying out an analysis by quantile clearly shows that this evolution is driven by outliers with vary large exaggerations. The yearly maximum exaggeration have increased in recent years.
Show code
retro_analysis_pubdate %>%
filter(percentage == 0.75) %>%
group_by(year = year(pub_date), percentage) %>%
summarise(
type_m = quantile(type_m, na.rm = TRUE),
quantile = paste("Quantile:", seq(0, 1, 0.25)),
n = n(),
groups = ".drop"
) %>%
# filter(quantile > 0.8) %>%
ggplot() +
geom_point(aes(x = year, y = type_m)) +
# geom_smooth(size = 0.3) +
# geom_smooth(size = 0.3, formula = y ~ x + I(x^2)) +
facet_wrap(~ quantile, scales = "free_y") +
labs(
title = "Evolution exaggeration with publication date, by quantile",
subtitle = "If the magnitude of true effect is half of the measured effect",
x = "Publication date",
y = "Exaggeration"
)
Journal and fields
We then look into the distribution of articles in journals and fields. We filter out articles from life sciences and social sciences & humanities journals since only a very limited number of articles have been published in such journals.
Show code
set_mediocre_all(pal = "leo", second_pair = TRUE)
articles_low_adequate %>%
filter(!(subject_area %in% c("Life Sciences", "Social Sciences & Humanities"))) %>%
filter(!is.na(subject_area)) %>%
group_by(subject_area, low_power) %>%
mutate(n_low_power = sum(low_power)/sum(n())) %>%
ungroup() %>%
ggplot() +
geom_bar(
aes(y = fct_reorder(subject_area, n_low_power, mean), fill = low_power_phrase),
position = "fill",
) +
labs(
x = "Proportion of articles",
y = NULL,
title = "Journals fields in which articles have been published",
subtitle = "Comparison between effects that have adequate power or not",
fill = ""
) 
Show code
articles_low_adequate %>%
unnest(subsubject_area) %>%
mutate(subsubject_area = fct_lump_n(subsubject_area, 20)) %>%
filter(subsubject_area != "Other") %>%
group_by(subsubject_area, low_power) %>%
mutate(n_low_power = sum(low_power)/sum(n())) %>%
ungroup() %>%
ggplot() +
geom_bar(
aes(y = fct_reorder(subsubject_area, n_low_power, mean), fill = low_power_phrase),
position = "fill"
) +
labs(
x = "Proportion of articles",
y = NULL,
title = "Main journal subjects in which effects have been published",
subtitle = "Comparison between effects that have adequate power or not",
fill = ""
) 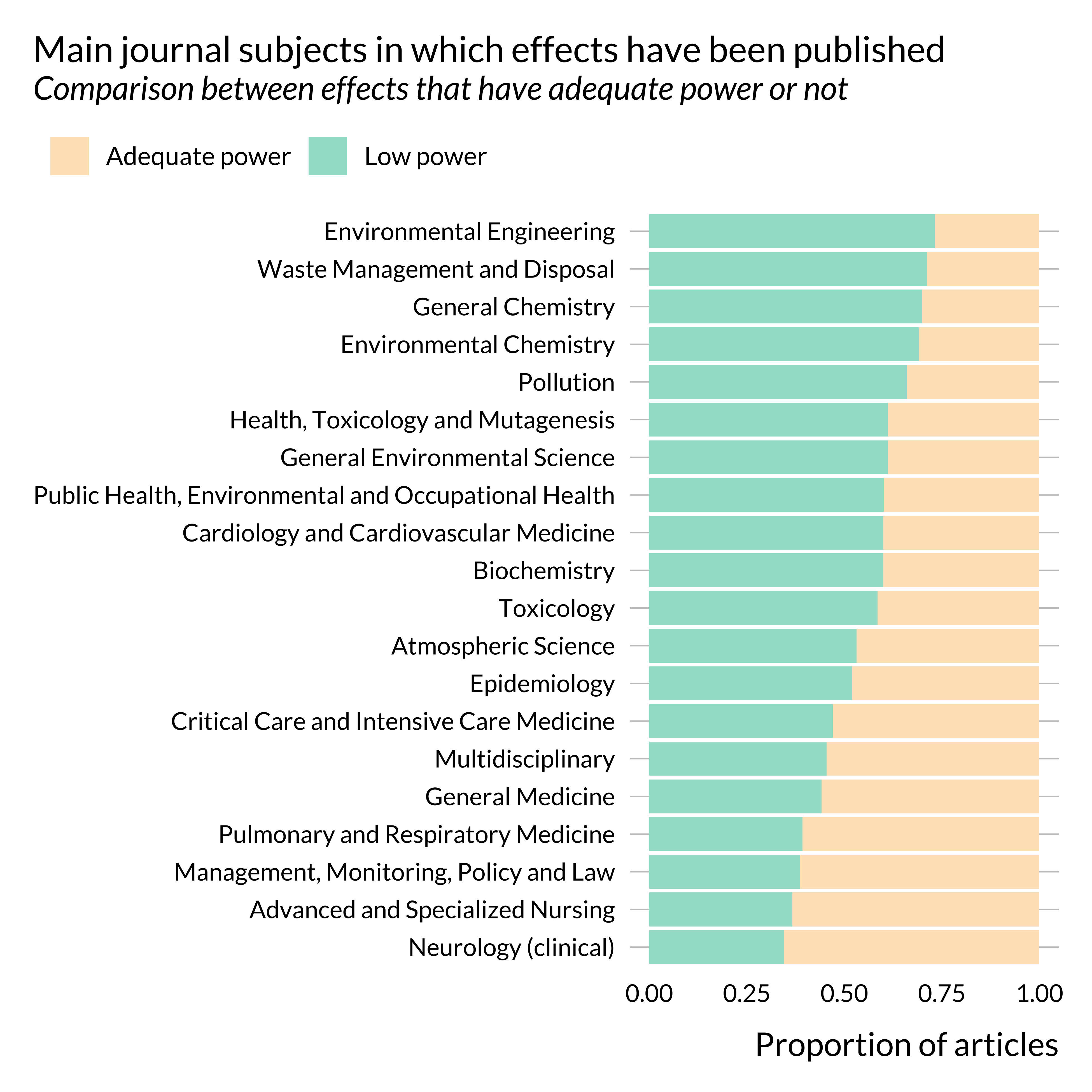
It seems that articles published in health sciences journals are less prone to power issues than articles published in other type_s of journals. This is somehow confirmed when looking at more precise subjects: the proportion of articles displaying low power is much lower in medicine journals than in “environment” and “chemistry” journals.
Some of the heterogeneity may come from the leniency of the journals with regards to these issues. Interestingly, not many fields have a very low rate of articles with low power. This might reveal an across the board lack of awareness of power issues. Yet, while our knowledge of the medicine literature is extremely limited, we seem to remember that, when applying for randomized experiments, researchers in medicine have to perform power calculations in order to properly design their study. Some of them therefore pay carefull attention to power issues and this might explain the lower rate of articles with low power in such journals.
Themes
We then investigate whether the themes appearing in the abstracts are different in articles with adequate or low power.
Show code
theme_effect <- articles_low_adequate %>%
unnest_tokens(word, abstract, to_lower = TRUE) %>%
anti_join(tidytext::stop_words, by = "word") %>%
group_by(word, low_power) %>%
mutate(n_articles_word = length(unique(doi))) %>%
ungroup() %>%
select(word, low_power, low_power_phrase, n_articles_word) %>%
distinct() %>%
group_by(word) %>%
mutate(tot_n_articles_word = sum(n_articles_word, na.rm = TRUE)) %>%
ungroup() %>%
filter(tot_n_articles_word > 450) %>%
ungroup() %>%
# mutate(has_effect = ifelse(has_effect, "Effect detected", "Effect not detected")) %>%
mutate(word = reorder(word, n_articles_word))
theme_effect %>%
ggplot(aes(x = word, fill = low_power_phrase)) +
geom_col(
data = subset(theme_effect, low_power),
aes(y = n_articles_word)
) +
geom_col(
data = subset(theme_effect, !low_power),
aes(y = -n_articles_word),
position = "identity"
) +
scale_y_continuous(labels = abs) +
coord_flip() +
labs(
x = NULL,
y = "Number of abstracts containing a given word",
title = "Words appearing in the more abstracts",
subtitle = "Comparison between articles with and without detected effect",
fill = ""
) 
There does not seem to be a clear difference in the terms used in abstracts for articles with low and adequate power. The only noticeable difference, not visible in this graph, is the use of the term “relative”. Articles with low power mention it much less that articles with adequate power. This difference is rather unclear.
Pollutant
We also look into potential disparities in terms of pollutant:
Show code
articles_low_adequate %>%
unnest(pollutant) %>%
filter(!is.na(pollutant)) %>%
group_by(pollutant, low_power) %>%
mutate(n_low_power = sum(low_power)/sum(n())) %>%
ungroup() %>%
ggplot() +
geom_bar(
aes(y = fct_reorder(pollutant, n_low_power, mean), fill = low_power_phrase),
position = "fill"
) +
labs(
x = "Proportion of articles",
y = NULL,
title = "Power of studies depending on the pollutant considered",
subtitle = "Comparison between articles studing a different pollutants",
fill = ""
)
There does not seem to be stark differences by pollutant type. While some differences seem to appear for BC and Air Quality Index, these pollutants are only studied in a limited sample of studies.
Outcome
We then compare the power as a function of the outcome studied (mortality or hospital admissions).
Show code
articles_low_adequate %>%
unnest(outcome) %>%
filter(!is.na(outcome)) %>%
ggplot() +
geom_bar(aes(outcome, fill = low_power_phrase), position = "fill") +
labs(
x = NULL,
y = "Proportion of articles",
title = "Power of studies depending on the outcome considered",
subtitle = "Comparison between articles with low and adequate power",
fill = ""
) 
There does not seem to be any heterogeneity along this dimension.
Subpopulation
We then turn to the sub-population studied.
Show code
articles_low_adequate %>%
unnest(subpop) %>%
# filter(!is.na(subpop)) %>%
mutate(subpop = ifelse(is.na(subpop), "Unknown", subpop)) %>%
ggplot() +
geom_bar(aes(subpop, fill = low_power_phrase), position = "fill") +
labs(
x = NULL,
y = "Proportion of articles",
title = "Number of articles considering a given subpopulation",
subtitle = "Comparison between articles with low and adequate power",
fill = ""
) 
There does not seem to be stark variations along this dimension either.
Number of observations
Finally, we explore the link between power and the number of observations. Remember that, for a lot of articles, we were not able to recover information about the number of observations (number of cities or length of the study). Hence, these results are purely suggestive.
Show code
articles_low_adequate %>%
ggplot() +
geom_density(
aes(x = n_obs, color = low_power_phrase, fill = low_power_phrase),
alpha = 0.6
) +
labs(
title = "Distribution of the number of observations",
# subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated number of observations",
y = "Density",
color = NULL,
fill = NULL
) +
scale_x_log10() 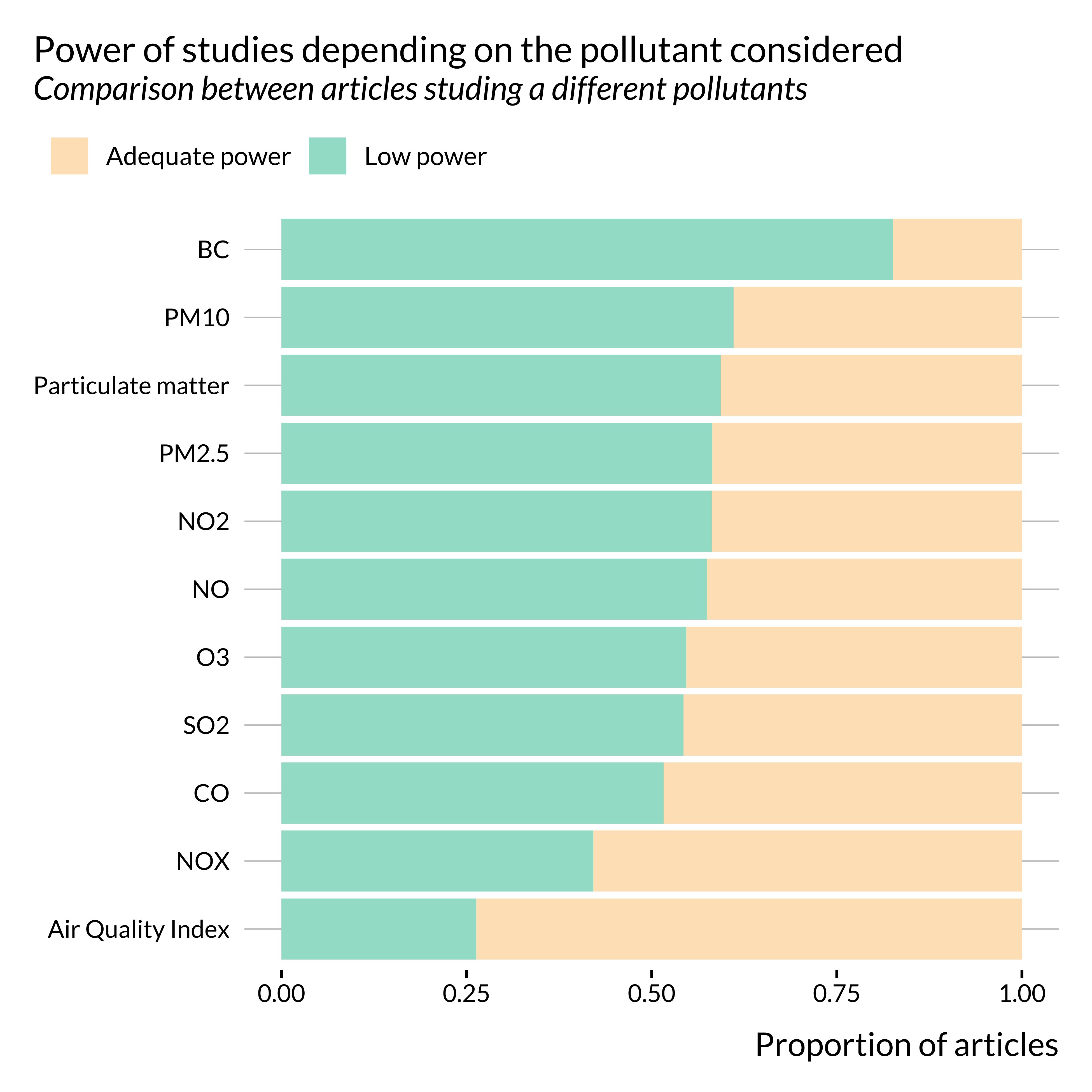
Show code
articles_low_adequate %>%
ggplot() +
geom_density(
aes(x = length_study, color = low_power_phrase, fill = low_power_phrase),
alpha = 0.6
) +
labs(
title = "Distribution of the length of the study",
# subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated length of the study (in days)",
y = "Density",
color = NULL,
fill = NULL
) +
scale_x_log10() 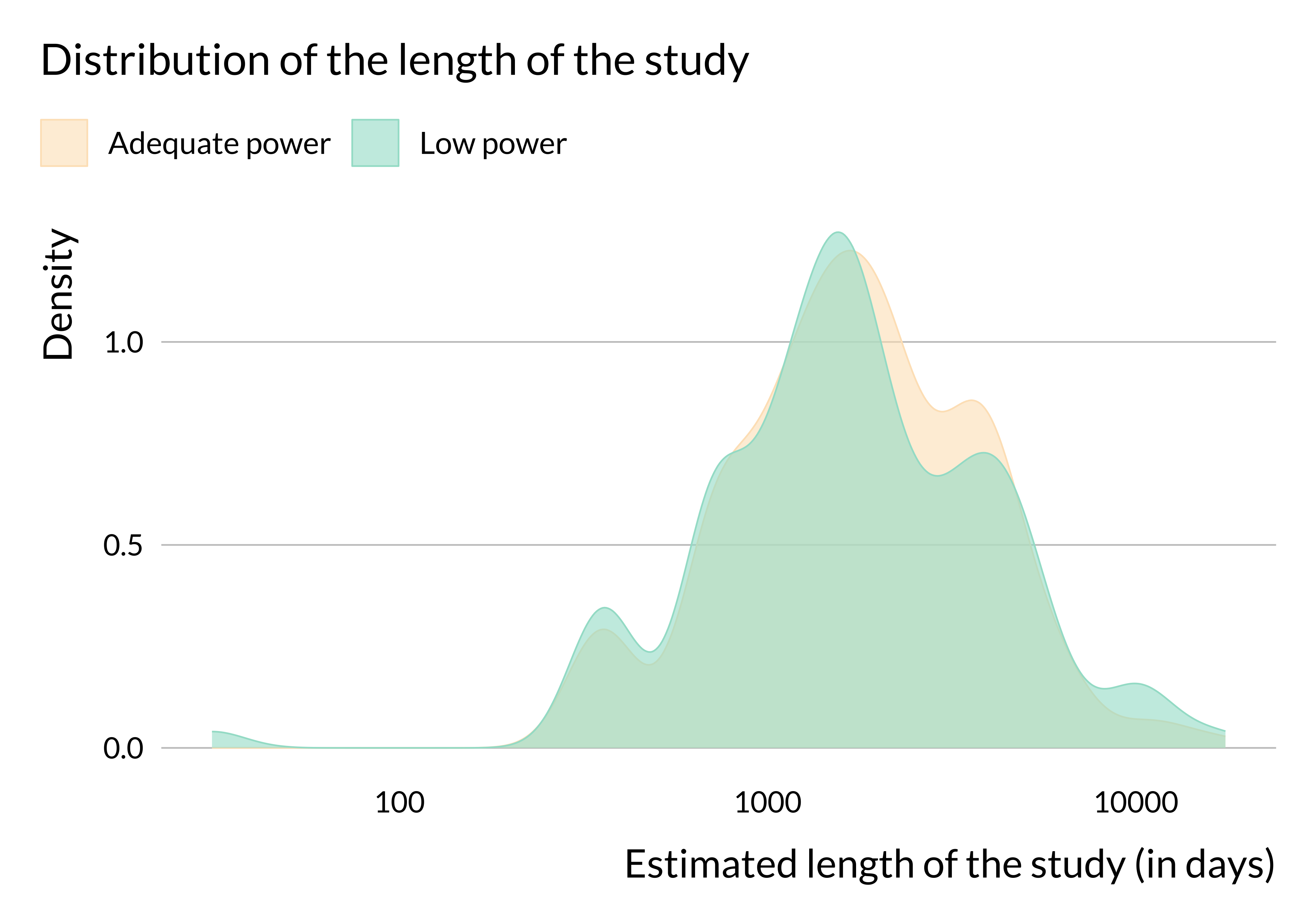
Show code
articles_low_adequate %>%
ggplot() +
geom_density(
aes(x = n_cities, color = low_power_phrase, fill = low_power_phrase),
alpha = 0.6
) +
labs(
title = "Distribution of the number of cities in each study",
# subtitle = "Comparison between articles for which an effect is retrieved and not",
x = "Estimated number of cities",
y = "Density",
color = NULL,
fill = NULL
) +
scale_x_log10() 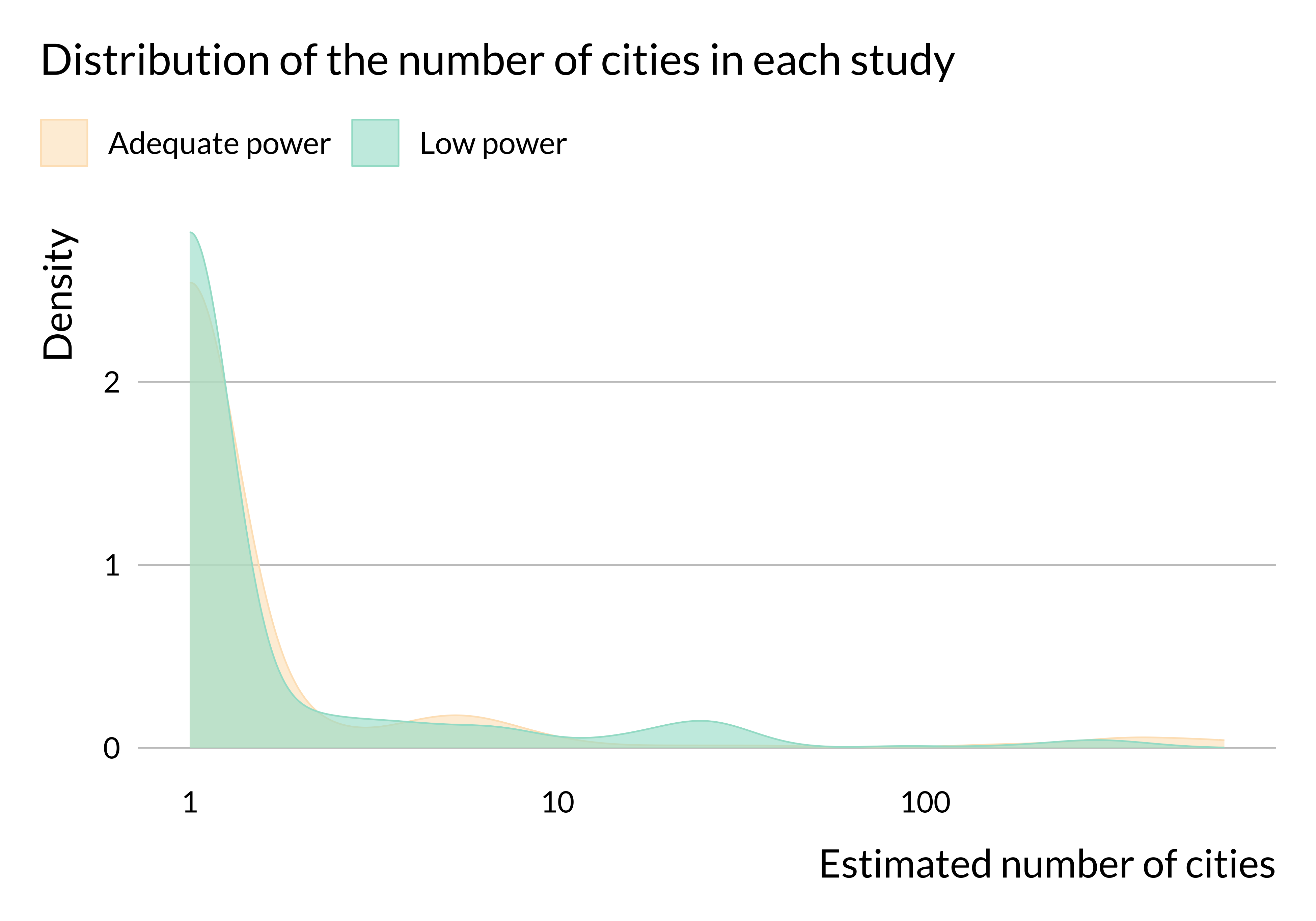
There does not seem to be substantial heterogeneity in terms of number of observations or length of the study period (at least in articles for which we were able to retrieve this information). We may not observe any difference in terms of number of observations because we do not have this information for many studies. We have retrieved more data about the number of cities considered and it seems that more studies with low power only consider one city. The data are imperfect but this result may come from the fact that estimates from studies focusing on one city are likely to be less precise than those from studies focusing on several cities. This would be due to a smaller number of observations.
Regression analysis
We then turn to regressions to run a more thorough analysis. I need to wrangle my data to run this analysis: I create dummies for the variables of interest and define reference categories.
I do not control for the length of the study or the number of cities for two reasons:
- These variable are mechanically correlated with power and for instance the number of observation may systematically vary in studies considering \(NO_x\) vs \(CO\) and if so, one would not want to control for the number of observations as they would be defining features of analyses of a certain type of pollutants,
- There are many missing values for these variables
Raw power
Show code
unnest_manual <- function(df, var) {
df |>
unnest({{ var }}) |>
mutate({{ var }} := ifelse(is.na({{ var }}), paste("missing", rlang::as_name(enquo(var)), sep = "_"), {{ var }})) |>
pivot_wider(names_from = {{ var }}, values_from = {{ var }}, values_fn = \(x) TRUE, values_fill = FALSE) |>
janitor::clean_names()
}
data_reg <- articles_low_adequate |>
mutate(
year = year(pub_date),
n_obs_1000 = n_obs/1000,
subject_area = ifelse(subject_area == "Life Sciences" | is.na(subject_area), "missing_subject_area", as.character(subject_area))
) |>
unnest_manual(subpop) |>
unnest_manual(outcome) |>
pivot_wider(names_from = subject_area, values_from = subject_area, values_fn = \(x) TRUE, values_fill = FALSE) |>
unnest_manual(pollutant)
vars <- names(data_reg |> select(elders:nox))
#remove ref categories
vars <- vars[-which(vars %in% c("missing_subpop", "emergency", "multidisciplinary", "missing_pollutant"))]
reg_power <- data_reg |>
feols(
data = _,
fml = power ~ year +
sw(elders + infants, #ref = missing ie the overall population
mortality + missing_outcome, #ref = emergency
health_sciences + physical_sciences + missing_subject_area, #ref = multidisciplinary
particulate_matter + air_quality_index + pm2_5 + o3 + pm10 + so2 + no2 + co + no + bc + nox,
elders + infants + mortality + missing_outcome + health_sciences + physical_sciences + missing_subject_area + particulate_matter + air_quality_index + pm2_5 + o3 + pm10 + so2 + no2 + co + no + bc + nox),
vcov = ~doi
)
names(reg_power) <- rep("power", length(reg_power))
modelsummary(reg_power, gof_omit = "IC|Adj|Log", stars = TRUE, coef_rename = \(x) str_remove(x, "TRUE")) | power | power | power | power | power | |
|---|---|---|---|---|---|
| (Intercept) | 365.714 | 533.952 | -82.642 | 283.793 | 28.679 |
| (417.944) | (421.841) | (424.751) | (468.424) | (488.468) | |
| year | -0.150 | -0.233 | 0.071 | -0.108 | 0.019 |
| (0.208) | (0.209) | (0.211) | (0.233) | (0.243) | |
| elders | -3.956 | -1.986 | |||
| (3.294) | (3.288) | ||||
| infants | -13.096 | -11.182 | |||
| (8.526) | (9.360) | ||||
| mortality | -4.889 | -4.536 | |||
| (3.002) | (2.958) | ||||
| missing_outcome | 9.645+ | 8.923+ | |||
| (5.082) | (5.273) | ||||
| health_sciences | 8.844** | 8.466** | |||
| (3.175) | (3.125) | ||||
| physical_sciences | -2.052 | -2.252 | |||
| (3.464) | (3.453) | ||||
| missing_subject_area | 4.459 | 5.598 | |||
| (4.546) | (4.503) | ||||
| particulate_matter | -2.609 | -3.372 | |||
| (2.930) | (2.861) | ||||
| air_quality_index | 16.236** | 20.074*** | |||
| (5.844) | (5.562) | ||||
| pm2_5 | -1.016 | -0.969 | |||
| (3.153) | (3.107) | ||||
| o3 | 0.747 | -0.072 | |||
| (2.935) | (2.902) | ||||
| pm10 | -6.376* | -5.470+ | |||
| (2.880) | (2.833) | ||||
| so2 | 3.754 | 3.627 | |||
| (3.570) | (3.679) | ||||
| no2 | -2.778 | -4.074 | |||
| (3.132) | (3.066) | ||||
| co | 4.795 | 4.294 | |||
| (4.089) | (4.206) | ||||
| no | -2.489 | -1.883 | |||
| (7.014) | (7.353) | ||||
| bc | -17.195+ | -16.419+ | |||
| (8.777) | (8.693) | ||||
| nox | 8.088 | 2.292 | |||
| (14.775) | (14.740) | ||||
| Num.Obs. | 1982 | 1982 | 1982 | 1982 | 1982 |
| R2 | 0.004 | 0.015 | 0.018 | 0.023 | 0.054 |
| RMSE | 33.19 | 33.01 | 32.97 | 32.88 | 32.35 |
| Std.Errors | by: doi | by: doi | by: doi | by: doi | by: doi |
|
|||||
From these regressions, we get that there does not seem to be major disparities apart from the fact that:
- Studies published in health science journals seem to have higher power than those published in other fields (or with missing field information)
- Studies interested considering air quality indexes seem to have higher power on average (and studies considering black carbon may have lower power). However, only 5 studies in our dataset consider such a pollutant.
Adequate power
Arguably, having an “adequate” power could matter most than power itself. I thus re-run the same analysis but with adequate_power as an outcome variable (and using a logit model).
Show code
reg_adeq <- data_reg |>
mutate(adeq_power = !low_power) |>
feglm(
data = _,
fml = adeq_power ~ year +
sw(elders + infants, #ref = missing ie the overall population
mortality + missing_outcome, #ref = emergency
health_sciences + physical_sciences + missing_subject_area, #ref = multidisciplinary
particulate_matter + air_quality_index + pm2_5 + o3 + pm10 + so2 + no2 + co + no + bc + nox,
elders + infants + mortality + missing_outcome + health_sciences + physical_sciences + missing_subject_area + particulate_matter + air_quality_index + pm2_5 + o3 + pm10 + so2 + no2 + co + no + bc + nox),
vcov = ~doi,
family = binomial(link = "logit")
)
names(reg_adeq) <- rep("adeq_power", length(reg_adeq))
modelsummary(reg_adeq, gof_omit = "IC|Adj|Log", stars = TRUE, coef_rename = \(x) str_remove(x, "TRUE"))| adeq_power | adeq_power | adeq_power | adeq_power | adeq_power | |
|---|---|---|---|---|---|
| (Intercept) | 22.294 | 35.435 | -0.868 | 25.974 | 14.011 |
| (25.079) | (25.900) | (25.699) | (28.314) | (30.459) | |
| year | -0.011 | -0.018 | 0.000 | -0.013 | -0.007 |
| (0.012) | (0.013) | (0.013) | (0.014) | (0.015) | |
| elders | -0.331 | -0.210 | |||
| (0.209) | (0.216) | ||||
| infants | -0.827 | -0.721 | |||
| (0.668) | (0.728) | ||||
| mortality | -0.406* | -0.395* | |||
| (0.179) | (0.186) | ||||
| missing_outcome | 0.558+ | 0.510 | |||
| (0.315) | (0.335) | ||||
| health_sciences | 0.444* | 0.440* | |||
| (0.191) | (0.194) | ||||
| physical_sciences | -0.159 | -0.143 | |||
| (0.214) | (0.222) | ||||
| missing_subject_area | 0.155 | 0.268 | |||
| (0.271) | (0.275) | ||||
| particulate_matter | -0.111 | -0.154 | |||
| (0.179) | (0.181) | ||||
| air_quality_index | 1.319** | 1.580*** | |||
| (0.414) | (0.400) | ||||
| pm2_5 | 0.068 | 0.054 | |||
| (0.192) | (0.197) | ||||
| o3 | 0.132 | 0.089 | |||
| (0.182) | (0.185) | ||||
| pm10 | -0.336+ | -0.274 | |||
| (0.177) | (0.181) | ||||
| so2 | 0.228 | 0.222 | |||
| (0.224) | (0.239) | ||||
| no2 | -0.198 | -0.300 | |||
| (0.196) | (0.198) | ||||
| co | 0.298 | 0.271 | |||
| (0.252) | (0.269) | ||||
| no | -0.119 | -0.091 | |||
| (0.421) | (0.464) | ||||
| bc | -1.214 | -1.183 | |||
| (0.854) | (0.846) | ||||
| nox | 0.807 | 0.497 | |||
| (0.836) | (0.868) | ||||
| Num.Obs. | 1982 | 1982 | 1982 | 1982 | 1982 |
| R2 | 0.005 | 0.015 | 0.011 | 0.017 | 0.041 |
| RMSE | 0.49 | 0.49 | 0.49 | 0.49 | 0.48 |
| Std.Errors | by: doi | by: doi | by: doi | by: doi | by: doi |
|
|||||
The results for raw power seem to carry, even though studies considering “mortality” as an outcome may have a lower rate of adequate power than those considering hospital admissions.