In this document, we carry out a retrospective power analysis of the causal inference literature on the acute health effects of air pollution.
We used an extensive search strategy on Google Scholar, PubMed, and IDEAS to retrieve studies that (i) focus on the short-health effects of air pollution on mortality and morbidity outcomes, and (ii) rely on a causal inference method. We exclude the very recent literature on the effects of air pollution on COVID-19 health outcomes. We found a corpus of 36 relevant articles. For each study, we retrieved the method used by the authors, which health outcome and air pollutant they consider, the point estimate and the standard error of results. We coded all main results but also those on heterogeneous effects by age categories and control outcomes (“placebo tests”).
Our document is organized as follows:
In the first section, we describe the coded variables and explain how we standardize effect sizes.
In the second section, we provide two pieces of evidence for publication bias in the literature.
In the third section, we compute the statistical power, the exaggeration and the probability to make a type S error for each paper using different guesses of true effect sizes. For this task, we rely on the very convenient retrodesign package.
Set-Up
Packages and Data
Show the packages used
library("groundhog")
packages <- c(
"here",
"tidyverse",
"knitr",
"retrodesign",
"kableExtra",
"patchwork",
"DT",
"mediocrethemes"
# "vincentbagilet/mediocrethemes"
)
# groundhog.library(packages, "2022-11-28")
lapply(packages, library, character.only = TRUE)
set_mediocre_all(pal = "leo")We load the literature review data and export it to .csv. You can download it here.
# load literature review data
data_lit_causal <- readRDS(here("data", "lit_causal", "data_lit_causal.rds"))Description of Coded Variables
We retrieved data 537 estimates from 36 articles. For each paper, we coded 25 variables:
paper_label: the first author and publication date of the article. This is the identifier of a study.paper_estimate_id: this is the unique identifier of a result. The median number of results reported by studies is 11.url: the internet link of the publication.publication_year: year of publication. Papers we consider were published between 2011 and 2022.field: whether the variable was published in economics or in epidemiology. 78 of studies are published in economics journals, the rest being published in epidemiology/public health journals.context: the location of the study.empirical_strategy: the empirical strategy used by researchers (“conventional time series model”, “reduced-form”, “difference-in-differences,”instrumental variable”, etc…). We display below the 5 most used empirical strategies for our 537 estimates:
Show code
data_lit_causal %>%
group_by(empirical_strategy) %>%
summarise(n = n()) %>%
mutate(proportion = n / sum(n) * 100,
proportion = round(proportion, 0)) %>%
select(empirical_strategy, proportion) %>%
arrange(-proportion) %>%
slice(1:5) %>%
rename("Empirical Strategy" = empirical_strategy, "Proportion (%)" = proportion) %>%
kable(., align = c("l", "c")) %>%
kable_styling(position = "center")| Empirical Strategy | Proportion (%) |
|---|---|
| instrumental variable | 44 |
| reduced-form | 17 |
| conventional time series | 14 |
| multi pollutant iv-lasso models | 6 |
| difference in differences | 5 |
outcome: the health outcome studied.outcome_type: whether the health outcome is a mortality or morbidity outcome. 43% of outcomes are related to mortality.outcome_subgroup: indicates which age group is studied.control_outcome: dummy equals to 1 if the health outcome is an outcome that should not be affected by the treatment of interest.independent_variable: the treatment of interest.temporal_scale: indicates at which temporal scale data are recorded (e.g., at the daily level).sample_size: number of observations.increase_independent_variable: the increase in the independent variable considered (e.g., a 1 \(\mu g/m^3\) increase in an air pollutant concentration).independent_variable_dummy: indicates whether the independent variable is binary. 27% of estimates are for a binary treatment.is_standardized: indicates whether the estimates have already been standardized. 3% of estimates are already standardized.log_outcome: is the estimate expressed in relative term. 25% of estimates represent relative increase in the health outcome.mean_outcomeandsd_outcome: the average and the standard deviation of the outcome.mean_independant_variableandsd_independent_variable: the average and standard deviation of the treatment of interest.estimateandstandard_error: the values of the estimate and its standard error.first_stage_statistic: the first stage \(F\)-statistic.source_summary_stats: where we retrieve in the paper the figures on the average and standard deviation of variables.source_results: where we retrieve in the paper the figures on the estimates and standard errors.remarks: remarks on whether we have to do some computations on our own to retrieve the relevant information. For instance, we had to infer for very few papers the mean and standard deviation of a pollutant or an health outcome with statistics such as the median and the quartiles. We use the formula found here.open_data: whether the data are available to reproduce the findings of the study. Only 12% of results are directly reproducible.
The data set is as follows:
Computing Standardized Effect Sizes
We standardize the effect sizes using the standard deviations of the independent and outcome variables:
- If we denote \(\beta_{unstandardized}\) the unstandardized estimate, SD\(_{X}\) the standard deviation of the treatment and SD\(_{Y}\) the standard deviation of the health outcome, the standardized estimate is equal to \(\beta_{standardized} = \beta \times \frac{SD_{X}}{SD_{Y}}\).
- The standardized standard error SE\(_{standardized}\) is then equal to \(SE_{standardized} = SE_{unstandardized} \times \frac{\beta_{standardized}}{\beta_{unstandardized}}\).
In the case where authors used linear regression models with log-transformed variables, we rely on the formulas provided by Rodríguez-Barranco et al. (2017) to standardize the effect size.
Show code
# standardize log models
data_lit_causal_logs <- data_lit_causal %>%
filter(log_outcome == 1) %>%
mutate(
estimate_unlog = (exp(estimate) - 1) * mean_outcome,
ci_upper_95_unlog = (exp(estimate + 1.96 * standard_error) - 1) * mean_outcome,
standard_error_unlog = (ci_upper_95_unlog - estimate_unlog) / 1.96
) %>%
mutate(
standardized_estimate = case_when(
is_standardized == 0 &
independent_variable_dummy == 0 ~ estimate_unlog * sd_independent_variable / sd_outcome,
is_standardized == 0 &
independent_variable_dummy == 1 ~ estimate_unlog / sd_outcome,
is_standardized == 1 ~ estimate_unlog
),
standardized_standard_error = case_when(
is_standardized == 0 ~ standard_error_unlog * standardized_estimate / estimate_unlog,
is_standardized == 1 ~ standard_error_unlog
)
) %>%
select(paper_estimate_id,
standardized_estimate,
standardized_standard_error)
# standardize other models
data_lit_causal_not_logs <- data_lit_causal %>%
filter(log_outcome != 1) %>%
mutate(
standardized_estimate = case_when(
is_standardized == 0 &
independent_variable_dummy == 0 ~ estimate * sd_independent_variable / sd_outcome,
is_standardized == 0 &
independent_variable_dummy == 1 ~ estimate / sd_outcome,
is_standardized == 1 ~ estimate
),
standardized_standard_error = case_when(
is_standardized == 0 ~ standard_error * standardized_estimate / estimate,
is_standardized == 1 ~ standard_error
)
) %>%
select(paper_estimate_id,
standardized_estimate,
standardized_standard_error)
# merge the two datasets
data_lit_causal_std <-
bind_rows(data_lit_causal_logs, data_lit_causal_not_logs) %>%
left_join(data_lit_causal, ., by = "paper_estimate_id") %>%
select(
paper_label:standard_error,
standardized_estimate,
standardized_standard_error,
first_stage_statistic:open_data
)
saveRDS(data_lit_causal_std, here::here(
"data",
"lit_causal",
"data_lit_causal_std.rds"
))We are able to standardize the effects of 63% of all estimates. We display below summary statistics on the distribution of the standardized effect sizes of causal inference methods:
Show code
# display sample sizes
summary_std <- data_lit_causal_std %>%
filter(!(empirical_strategy %in% c("conventional time series", "conventional time series - suggestive evidence"))) %>%
mutate(standardized_estimate = abs(standardized_estimate)) %>%
summarise(
"Min" = min(standardized_estimate, na.rm = TRUE),
"First Quartile" = quantile(standardized_estimate, na.rm = TRUE)[2],
"Mean" = mean(standardized_estimate, na.rm = TRUE),
"Median" = median(standardized_estimate, na.rm = TRUE),
"Third Quartile" = quantile(standardized_estimate, na.rm = TRUE)[4],
"Maximum" = max(standardized_estimate, na.rm = TRUE)
)
summary_std %>%
kable(., align = rep("c", 6)) %>%
kable_styling(position = "center")| Min | First Quartile | Mean | Median | Third Quartile | Maximum |
|---|---|---|---|---|---|
| 0 | 0.0193351 | 0.9527143 | 0.0763023 | 0.2724913 | 34.99225 |
Half of the studies estimate effect sizes below 0.08 standard deviation.
We plot below the ratio of 2SLS estimates over OLS estimates:
Show code
# compute ratio 2sls/ols
data_ratio_ols_iv <- data_lit_causal_std %>%
select(paper_label, empirical_strategy, outcome, independent_variable, estimate, standard_error) %>%
filter(empirical_strategy %in% c("conventional time series", "instrumental variable")) %>%
arrange(paper_label, outcome, independent_variable) %>%
group_by(paper_label, outcome, independent_variable) %>%
summarise(
ratio = estimate[2]/estimate[1],
ratio_se = standard_error[2]/standard_error[1]) %>%
drop_na(ratio, ratio_se)
# plot the distribution
graph_ratio_ols_iv <- data_ratio_ols_iv %>%
filter(ratio>-20 & ratio <20) %>%
ggplot() +
geom_linerange(aes(x = ratio, ymin = -0.5, ymax = 0.5), colour = "#0081a7", alpha = 0.8) +
geom_linerange(aes(x = 1, ymin = -0.5, ymax = 0.5), linewidth = 1.1, colour = "black") +
geom_linerange(aes(x = median(data_ratio_ols_iv$ratio), ymin = -0.5, ymax = 0.5), linewidth = 1.1, colour = "#f07167") +
# annotate(geom = "label", x = -2, y = 0.4, label = "OLS = 2SLS", colour = "black", fill="white", label.size = NA, label.r=unit(0, "cm"), size = 6) +
# geom_curve(aes(x = -2, y = 0.30,
# xend = 0.9, yend = 0),
# curvature = 0.3,
# arrow = arrow(length = unit(0.42, "cm")),
# colour = "black",
# lineend = "round") +
# annotate(geom = "label", x = 6, y = 0.4, label = "Median of Ratios", colour = "#f07167", fill="white", label.size = NA, label.r=unit(0, "cm"), size = 6) +
# geom_curve(aes(x = 6, y = 0.30,
# xend = 4, yend = 0),
# curvature = -0.3,
# arrow = arrow(length = unit(0.42, "cm")),
# colour = "#f07167",
# lineend = "round") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 21)) +
xlab("Ratio 2SLS Estimate/OLS Estimate") + ylab(NULL) +
ggtitle("Distribution of the Ratios of 2SLS over OLS Estimates", subtitle = "2SLS estimates are often much larger than OLS estimates.") +
theme(axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
panel.grid.major.y = element_blank())
# display the graph
graph_ratio_ols_iv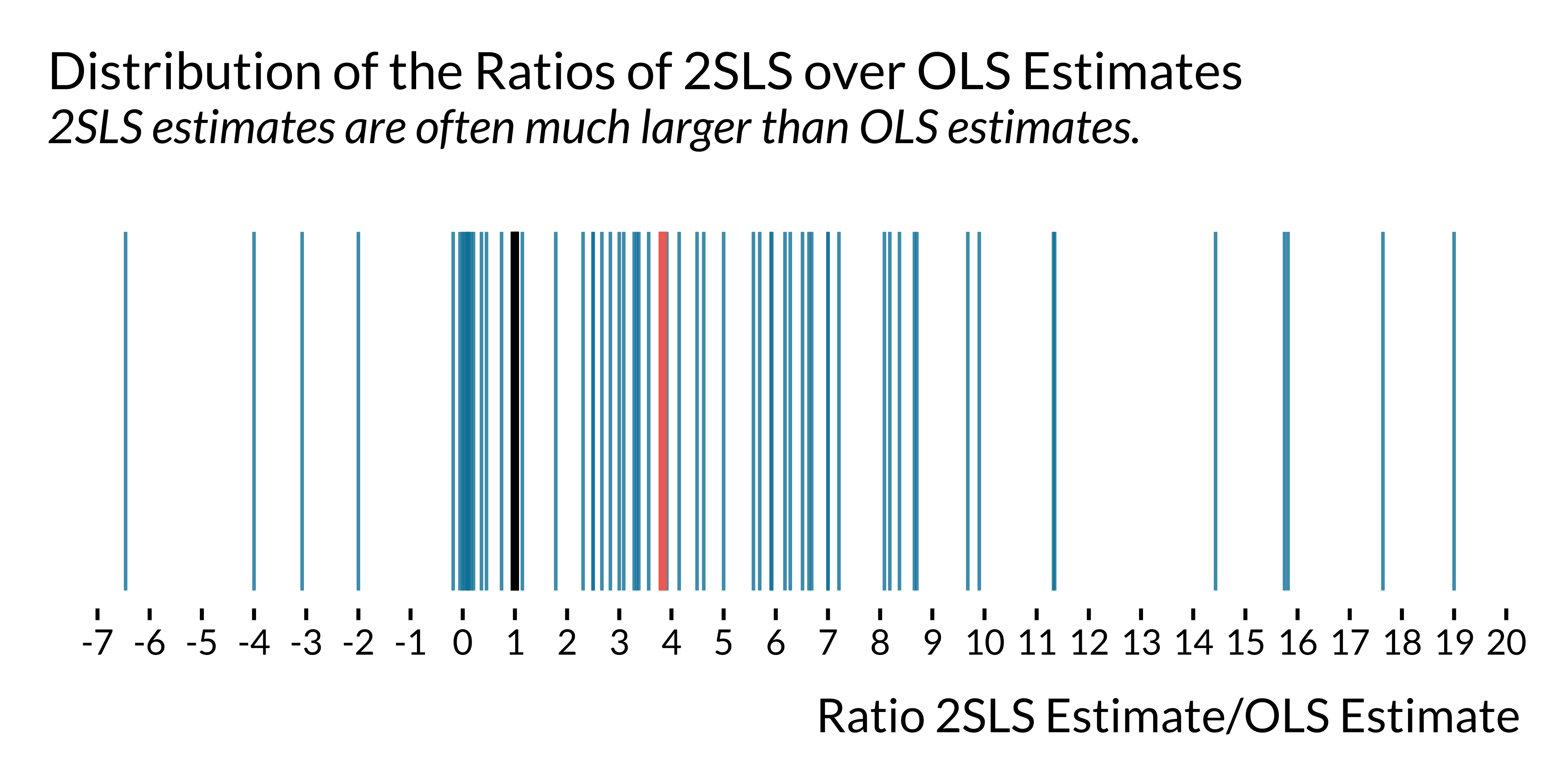
For half of the studies reporting both an IV estimate and an OLS estimate, the ratio of these respective estimates is larger than 3.8. The median ratio of the ratio of the standard errors is 3.8.
Evidence of Publication Bias
Distribution of t-statistics
We plot the distribution of weighted t-statistics by following Brodeur et al. (2020) where the weights are equal to the inverse of the number of tests presented in the same table multiplied by the inverse of the number of tables in the article.
Show code
data_lit_causal_caliper <- data_lit_causal_std %>%
filter(control_outcome != 1) %>%
mutate(table = stringr::word(source_results, 1, sep = " - ")) %>%
group_by(paper_label, table) %>%
mutate(n_tests = 1/n()) %>%
group_by(paper_label) %>%
mutate(n_tables = 1/length(unique(table))) %>%
ungroup() %>%
mutate(weight = n_tests*n_tables)
graph_distribution_t <- data_lit_causal_caliper %>%
ggplot(., aes(x = abs(estimate/standard_error), y = after_stat(density), weight = weight)) +
geom_histogram(bins = 60, colour = "white", alpha = 0.6) +
geom_density(bw = 0.35, fill = NA, size = 0.9) +
geom_vline(xintercept = 1.96, linewidth = 0.9, colour = "#f07167") +
# geom_curve(aes(x = 5, y = 0.37,
# xend = 2.1, yend = 0.27),
# curvature = -0.3,
# arrow = arrow(length = unit(0.42, "cm")),
# colour = "#f07167",
# lineend = "round") +
# annotate("text", x = 5.5, y = 0.38, label = "5% Significance Threshold", colour = "#f07167", size = 6) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 10)) +
labs(
title = "Weighted Distribution of the t-statistics",
subtitle = "More mass around the 1.96 threshold",
x = "t-statistic",
y = "Density"
)
ggsave(
filename = here::here(
"images",
"causal_lit_overview",
"graph_distribution_t.pdf"
),
width = 14,
height = 12,
units = "cm"
# device = cairo_pdf
)
graph_distribution_t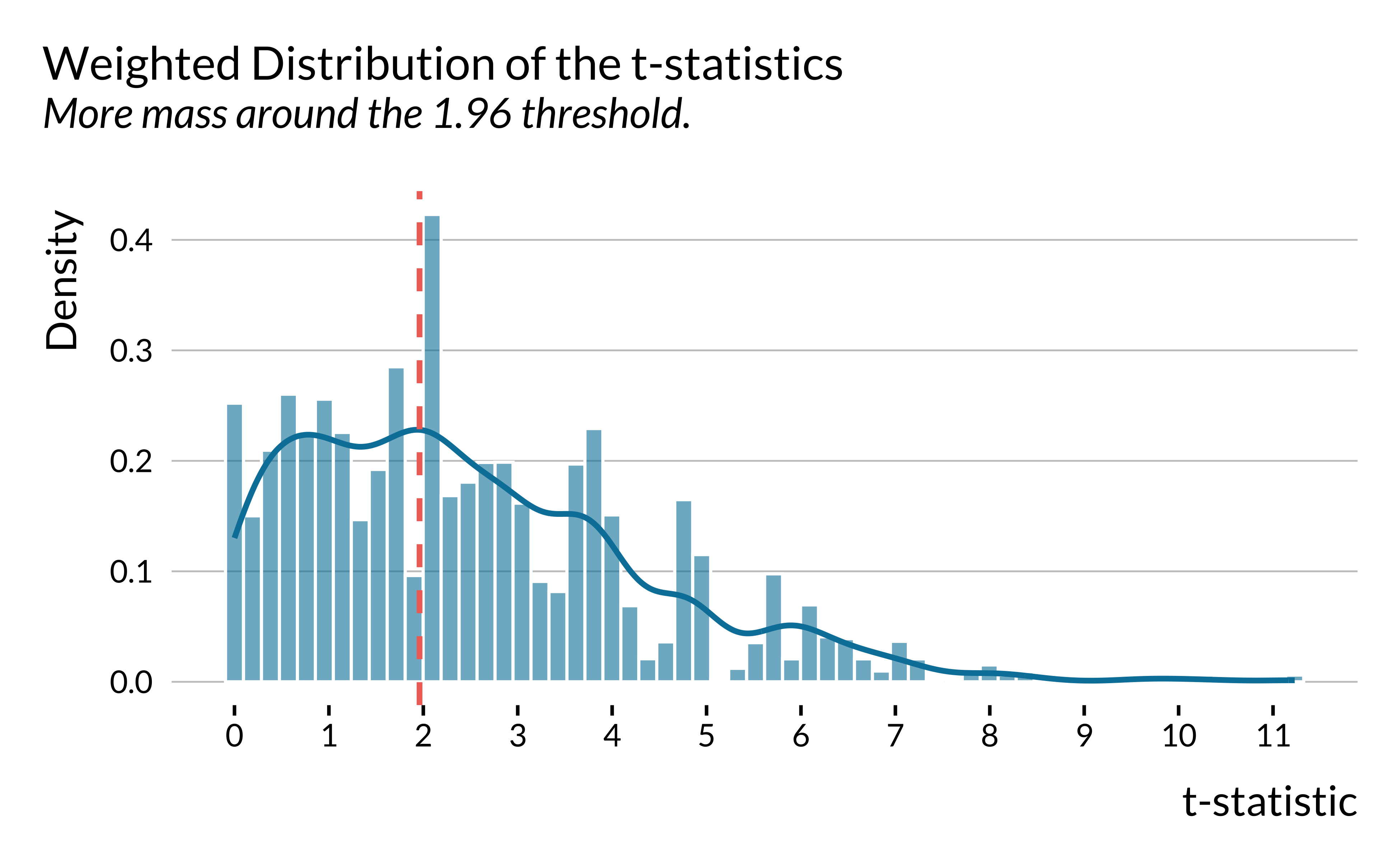
We then restrict the sample to studies published in economics journals. The figure remains essentially the same.
Show code
graph_distrib_t_econ <- data_lit_causal_caliper %>%
filter(control_outcome != 1) %>%
filter(field == "economics") %>%
ggplot(., aes(x = abs(estimate/standard_error), y = ..density.., weight = weight)) +
geom_histogram(bins = 60, colour = "white", alpha = 0.6) +
geom_density(bw = 0.35, fill = NA, size = 0.9) +
geom_vline(xintercept = 1.96, size = 0.9, colour = "#f07167") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 10)) +
labs(
title = "Weighted Distribution of the t-statistics",
subtitle = "Only estimates from economics journals",
x = "t-statistic",
y = "Density"
)
ggsave(
filename = here::here(
"images",
"causal_lit_overview",
"graph_distribution_t_econ.pdf"
),
width = 14,
height = 12,
units = "cm"
# device = cairo_pdf
)
graph_distrib_t_econ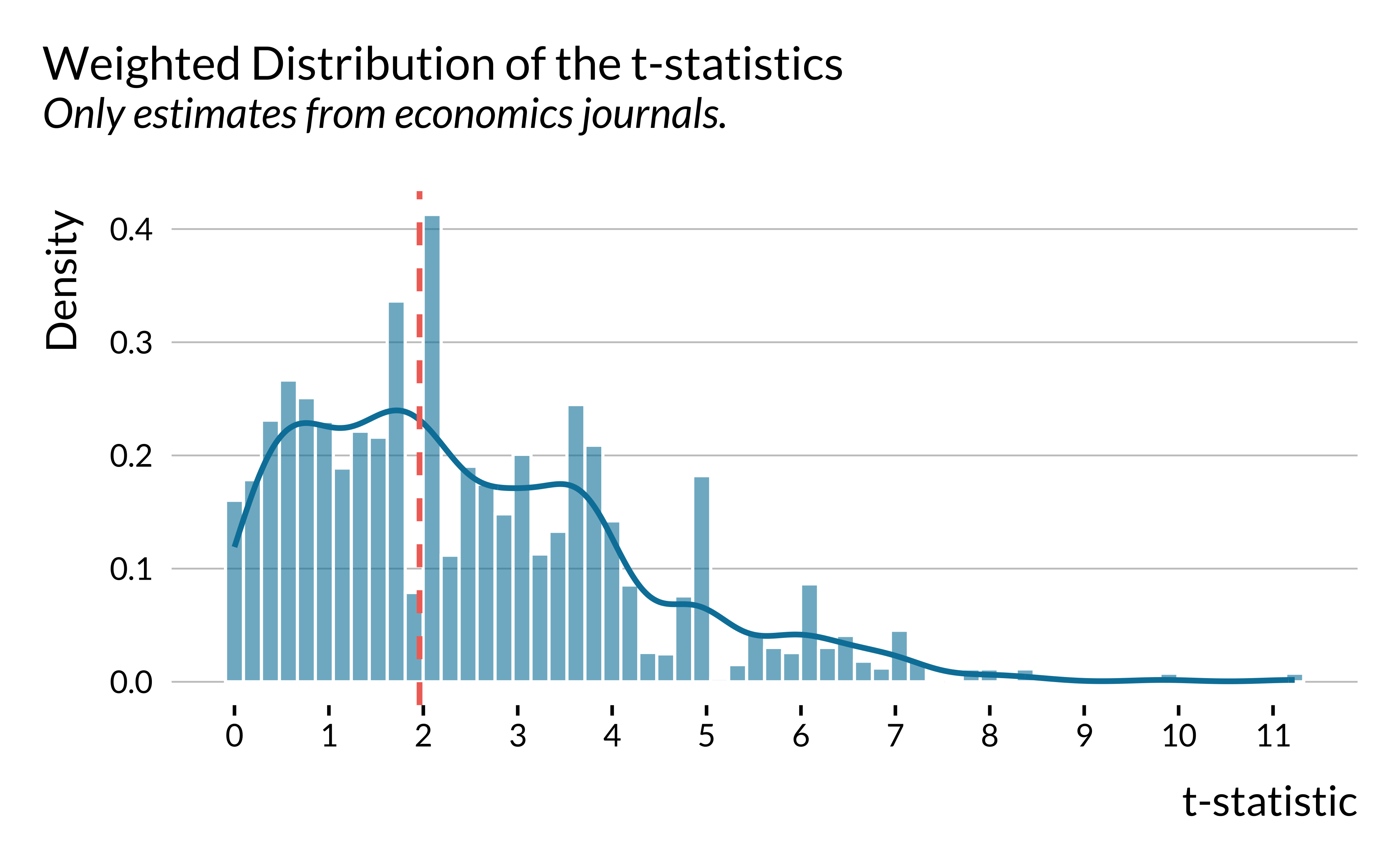
Caliper tests
We then implement formal caliper tests, as in Brodeur et al. (2020), themselves following Gerber and Malhotra (2008a). The idea behind these tests is to compare the number of test statistics just above and just below a significance threshold.
data_caliper <- data_lit_causal_caliper %>%
filter(control_outcome != 1) %>%
mutate(
t_stat = estimate / standard_error,
abs_t = abs(t_stat)
)
simple_caliper_test <- function(df, sign_level, window_width) {
threshold <- qnorm(1 - sign_level/2)
df_w <- df %>%
filter((abs_t >= threshold - window_width) & (abs_t <= threshold + window_width)) %>%
mutate(above = (abs_t >= threshold))
w_above <- df_w %>% filter(above) %>% pull(weight) %>% sum()
w_total <- sum(df_w$weight)
tibble(
sign_level,
window_width,
n_in_window = nrow(df_w),
n_above = df_w %>% filter(above) %>% nrow(),
n_below = df_w %>% filter(!above) %>% nrow(),
share_above = n_above / (n_above + n_below),
share_above_weighted = w_above / w_total
)
}
caliper_simple_results <- expand_grid(
sign_level = c(0.1, 0.05, 0.01),
window_width = c(0.20, 0.30, 0.50)
) %>%
pmap_dfr(simple_caliper_test, df = data_caliper)
caliper_simple_results |>
kable(digits = 2)| sign_level | window_width | n_in_window | n_above | n_below | share_above | share_above_weighted |
|---|---|---|---|---|---|---|
| 0.10 | 0.2 | 59 | 32 | 27 | 0.54 | 0.50 |
| 0.10 | 0.3 | 74 | 39 | 35 | 0.53 | 0.49 |
| 0.10 | 0.5 | 111 | 60 | 51 | 0.54 | 0.61 |
| 0.05 | 0.2 | 41 | 19 | 22 | 0.46 | 0.76 |
| 0.05 | 0.3 | 67 | 28 | 39 | 0.42 | 0.62 |
| 0.05 | 0.5 | 119 | 51 | 68 | 0.43 | 0.60 |
| 0.01 | 0.2 | 47 | 23 | 24 | 0.49 | 0.52 |
| 0.01 | 0.3 | 62 | 28 | 34 | 0.45 | 0.36 |
| 0.01 | 0.5 | 97 | 46 | 51 | 0.47 | 0.41 |
To ease reading, we make a graph to represent this data:
Show code
caliper_simple_results |>
mutate(
sign_level = as.factor(sign_level),
window_width = as.factor(window_width)
) |>
ggplot() +
geom_tile(
aes(x = sign_level, y = window_width, fill = share_above_weighted),
color = "white", linewidth = 2) +
coord_fixed() +
labs(
title = "Weighted share of observations above the threshold",
x = "Significance threshold",
y = "Window width",
fill = NULL
) +
scale_fill_gradient2(
midpoint = 0.5,
low = colors_mediocre$base,
mid = colors_mediocre$background,
high = colors_mediocre$complementary,
guide = guide_colourbar(theme = theme(
legend.key.width = unit(5, "cm"),
legend.key.height = unit(0.25, "cm"),
legend.ticks.length = unit(0.125, "cm"),
legend.title.position = "top", legend.margin = margin(t = -0.4, unit = "cm")))
) 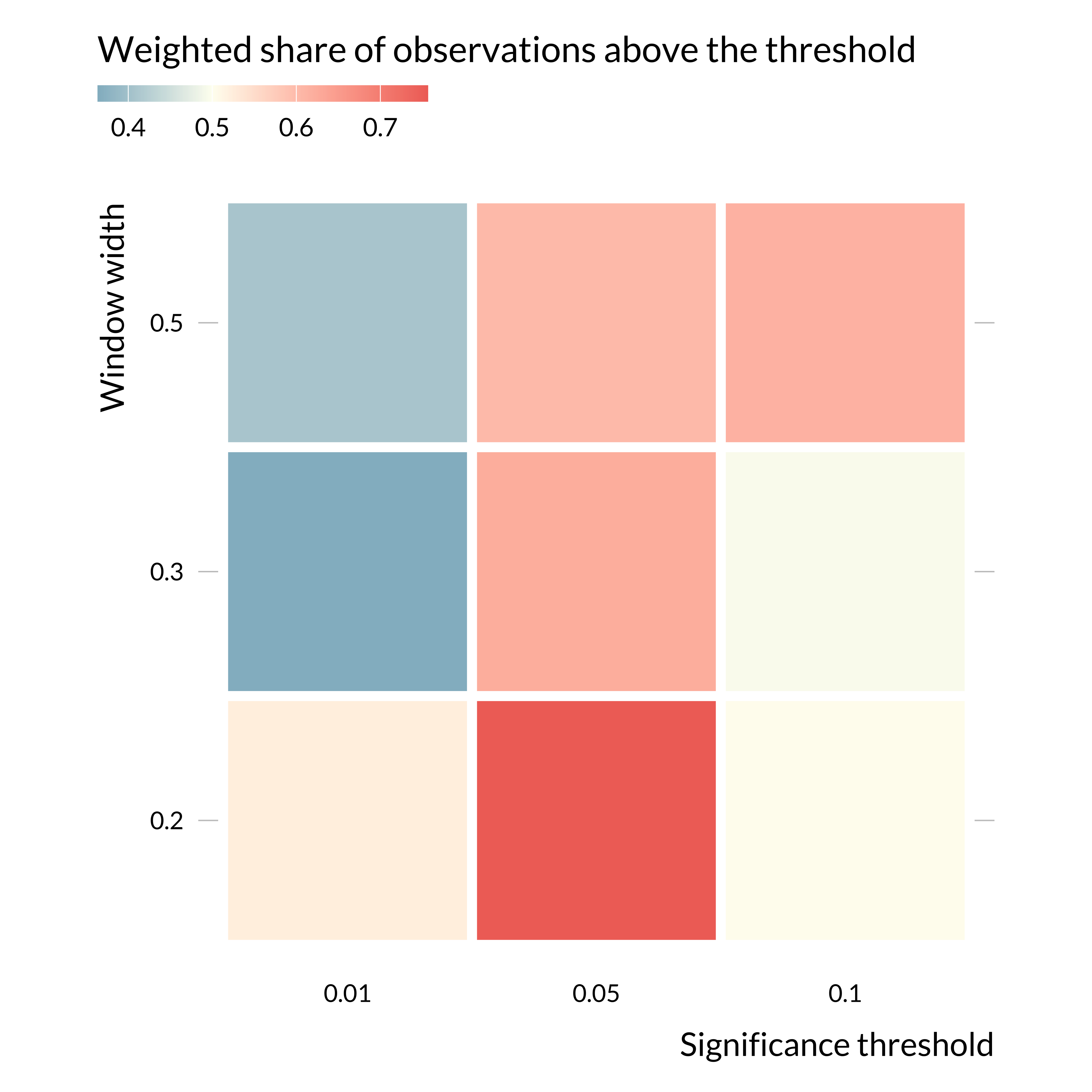
Focusing on the 5% threshold, as is the rest of the paper, the weights just above the threshold are larger than just below, suggesting selection on significance around this threshold. Interestingly, there does not seem to be selection on significance around the 1% threshold. That might be explained by the fact that the main threshold used in the economics literature is the 5% one.
Regardless, considering the relatively small number of observations (450 estimates), one might need to consider these results carefully.
Estimated Effect Sizes versus Precision
We plot below the relationship between the absolute values of standardized estimates and the inverse of their standard errors. We do not include control outcomes (“placebo” tests) and conventional time series estimates.
Show code
# make the graph of effect sizes versus precision
graph_effect_precision <- data_lit_causal_std %>%
mutate(inverse_se = 1 / standardized_standard_error) %>%
# drop control outcomes
filter(control_outcome==0) %>%
# drop conventional time series models
filter(!(empirical_strategy %in% c("conventional time series", "conventional time series - suggestive evidence"))) %>%
ggplot(.,
aes(x = inverse_se, y = abs(standardized_estimate))) +
geom_smooth(
method = "lm",
se = FALSE,
size = 0.9,
colour = "#f07167",
linetype = "dashed"
) +
geom_point(shape = 16, size = 1.8, alpha = 0.6) +
scale_x_log10(
breaks = scales::trans_breaks("log10", \(x) 10 ^ x),
labels = scales::trans_format("log10", scales::math_format(10 ^ .x))
) +
scale_y_log10(
breaks = scales::trans_breaks("log10", \(x) 10 ^ x),
labels = scales::trans_format("log10", scales::math_format(10 ^ .x))
) +
xlab("Precision (Inverse of Standard Errors)") + ylab("Standardized Effect Sizes") +
ggtitle("Standardized Estimates vs. Precision", subtitle = "Less precise studies find larger standardized effect sizes.")
ggsave(
graph_effect_precision,
filename = here::here(
"images",
"causal_lit_overview",
"graph_effect_precision.pdf"
),
width = 14,
height = 12,
units = "cm"
# device = cairo_pdf
)
# display the graph
graph_effect_precision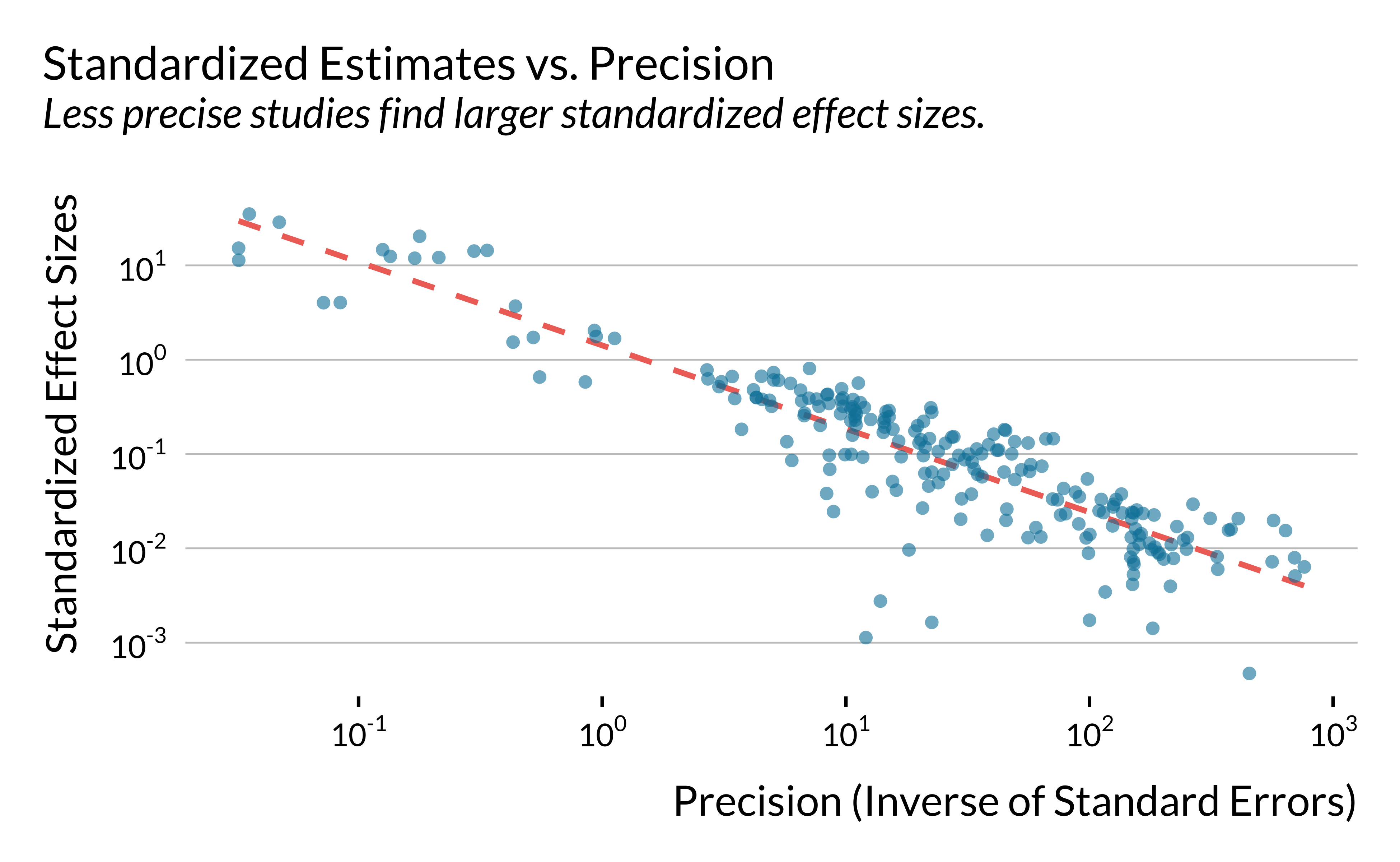
For economics journals, we then compare top 5 to other journals.
Show code
# make the graph of effect sizes versus precision
graph_effect_precision_field <- data_lit_causal_std %>%
mutate(
top5 = (journal %in% c("AER", "JPE", "Econometrica", "ReStud", "QJE")),
top5_name = ifelse(top5, "Top 5", "Other economics journal")
) |>
filter(field == "economics") |>
mutate(inverse_se = 1 / standardized_standard_error) %>%
# drop control outcomes
filter(control_outcome==0) %>%
# drop conventional time series models
filter(!(empirical_strategy %in% c("conventional time series", "conventional time series - suggestive evidence"))) %>%
ggplot(.,
aes(x = inverse_se, y = abs(standardized_estimate), color = top5_name)) +
geom_smooth(
method = "lm",
se = FALSE,
size = 0.9,
# colour = "#f07167",
linetype = "dashed"
) +
geom_point(shape = 16, size = 1.8, alpha = 0.6) +
scale_x_log10(
breaks = scales::trans_breaks("log10", \(x) 10 ^ x),
labels = scales::trans_format("log10", scales::math_format(10 ^ .x))
) +
scale_y_log10(
breaks = scales::trans_breaks("log10", \(x) 10 ^ x),
labels = scales::trans_format("log10", scales::math_format(10 ^ .x))
) +
labs(
x = "Precision (Inverse of Standard Errors)",
y = "Standardized Effect Sizes",
title = "Standardized Estimates vs. Precision",
subtitle = "Comparison between econoics journals",
color = NULL
)
ggsave(
graph_effect_precision_field,
filename = here::here(
"images",
"causal_lit_overview",
"graph_effect_precision_field.pdf"
),
width = 14,
height = 12,
units = "cm"
# device = cairo_pdf
)
# display the graph
graph_effect_precision_field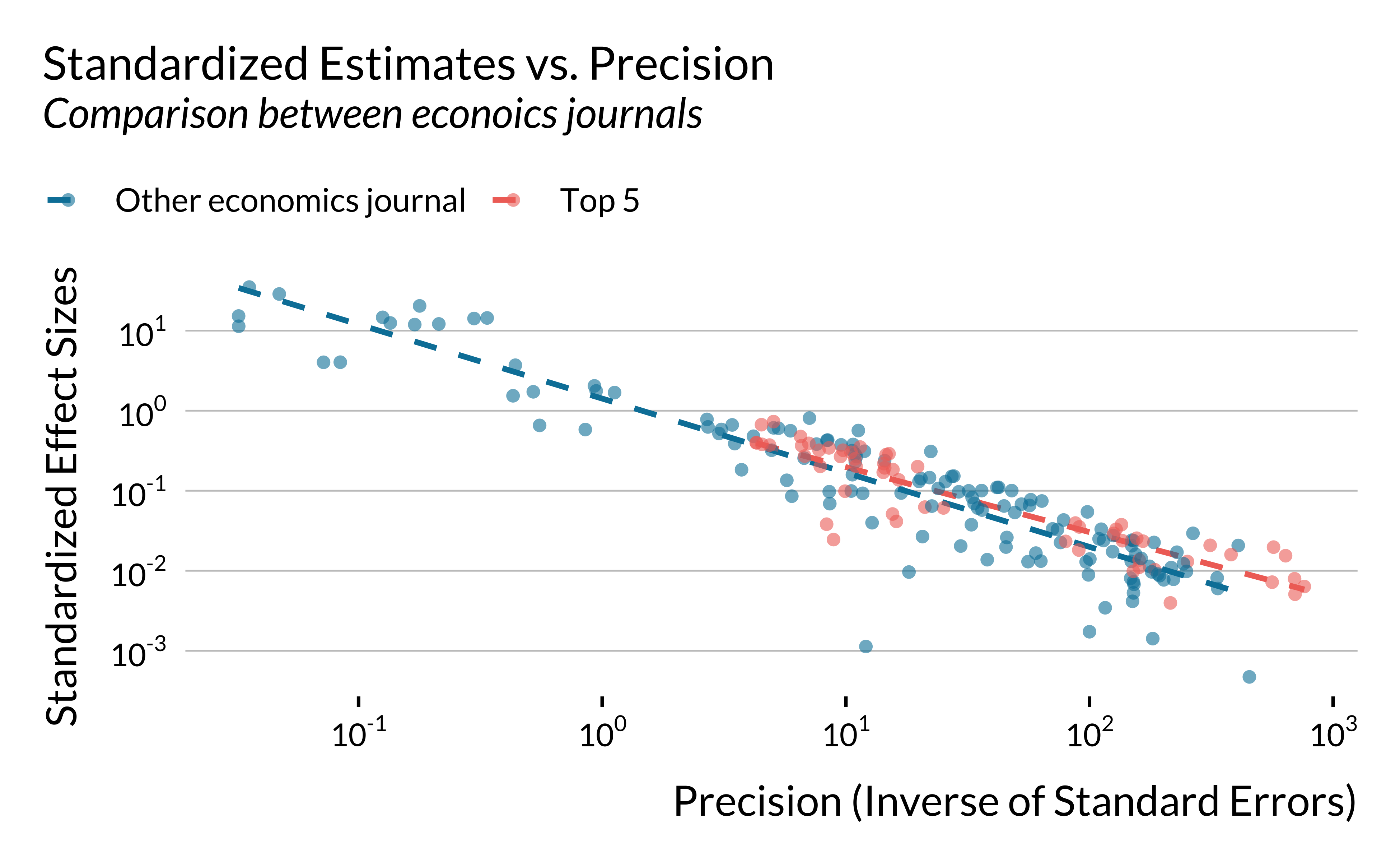
Computing Statistical Power, Exaggeration and Type S Errors
In this section, we compute the statistical power, the exaggeration ratio and the probability to make a type S error for each study. We rely on the retrodesign package.
To compute the three metrics, we need to make an assumption about the true effect size of each study:
- First, we assess whether the design of each study would be robust enough to detect an effect size that is a bit lower than the observed estimate.
- Second, for instrumental variable strategy, we take the OLS estimate as the true value of the 2SLS causal estimand.
Overview
We define the true effect sizes as a decreasing fraction of the estimates. We want to see how the overall distributions of the three metrics evolve with as we decrease the hypothesized true effect size.
# test exaggeration and type s errors
data_retrodesign <- data_lit_causal_std %>%
# drop control outcomes
filter(control_outcome == 0) %>%
# drop conventional time series models
filter(!(
empirical_strategy %in% c(
"conventional time series",
"conventional time series - suggestive evidence"
)
)) %>%
select(paper_label, paper_estimate_id, estimate, standard_error) %>%
# select statistical significant estimates at the 5% level
filter(abs(estimate / standard_error) >= 1.96)For each study, we compute the statistical power, the exaggeration ratio and the probability to make a type S error by defining their true effect sizes as decreasing fraction of the estimates.
# run retrospective power analysis for decreasing effect sizes
data_retrodesign_fraction <- data_retrodesign |>
crossing(percentage = seq(from = 30, to = 100) / 100) |>
mutate(hypothetical_effect_size = percentage * estimate) |>
mutate(
retro = map2(hypothetical_effect_size, standard_error,
\(x, y) retro_design_closed_form(x, y))
#retro_design returns a list with power, type_s, type_m
) |>
unnest_wider(retro) |>
mutate(power = power * 100) |>
pivot_longer(
cols = c(power, type_m, type_s),
names_to = "metric",
values_to = "value"
) %>%
mutate(
metric = case_when(
metric == "power" ~ "Statistical Power (%)",
metric == "type_m" ~ "Exaggeration Ratio",
metric == "type_s" ~ "Type S Error (%)"
)
)
# compute mean values of metrics for the entire literature
data_retrodesign_fraction_mean <- data_retrodesign_fraction %>%
group_by(metric, percentage) %>%
summarise(median_value = median(value))We then plot the power and the exaggeration ratio metrics for the different scenarios (we do not report Type S error as this issue is limited in this setting):
Show code
# make the graph of the retrospective power analysis
graph_retrodesign_causal_inf <- data_retrodesign_fraction %>%
filter(metric != "Type S Error (%)") %>%
ggplot(., aes(
x = percentage * 100,
y = value,
group = interaction(paper_estimate_id)
)) +
geom_line(colour = "#adb5bd", alpha = 0.2) +
geom_line(
data = data_retrodesign_fraction_mean %>%
filter(metric != "Type S Error (%)"),
aes(
x = percentage * 100,
y = median_value,
group = "l"
),
colour = "#0081a7",
size = 1.5
) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 4)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 5)) +
facet_wrap( ~ fct_rev(metric), scales = "free_y") +
labs(
x = "True Effect Size as Fraction of Observed Estimate (%)",
y= NULL
) +
theme(
panel.grid.major.y = element_blank(),
axis.ticks.y = element_line(size = 0.5, color = "black")
)
# save the graph
ggsave(
graph_retrodesign_causal_inf,
plot_annotation +
theme(plot.title = element_blank(),
plot.subtitle = element_blank()),
filename = here::here(
"images",
"causal_lit_overview",
"graph_retrodesign_causal_inf.pdf"
),
width = 18,
height = 10,
units = "cm"
# device = cairo_pdf
)
# display the graph
graph_retrodesign_causal_inf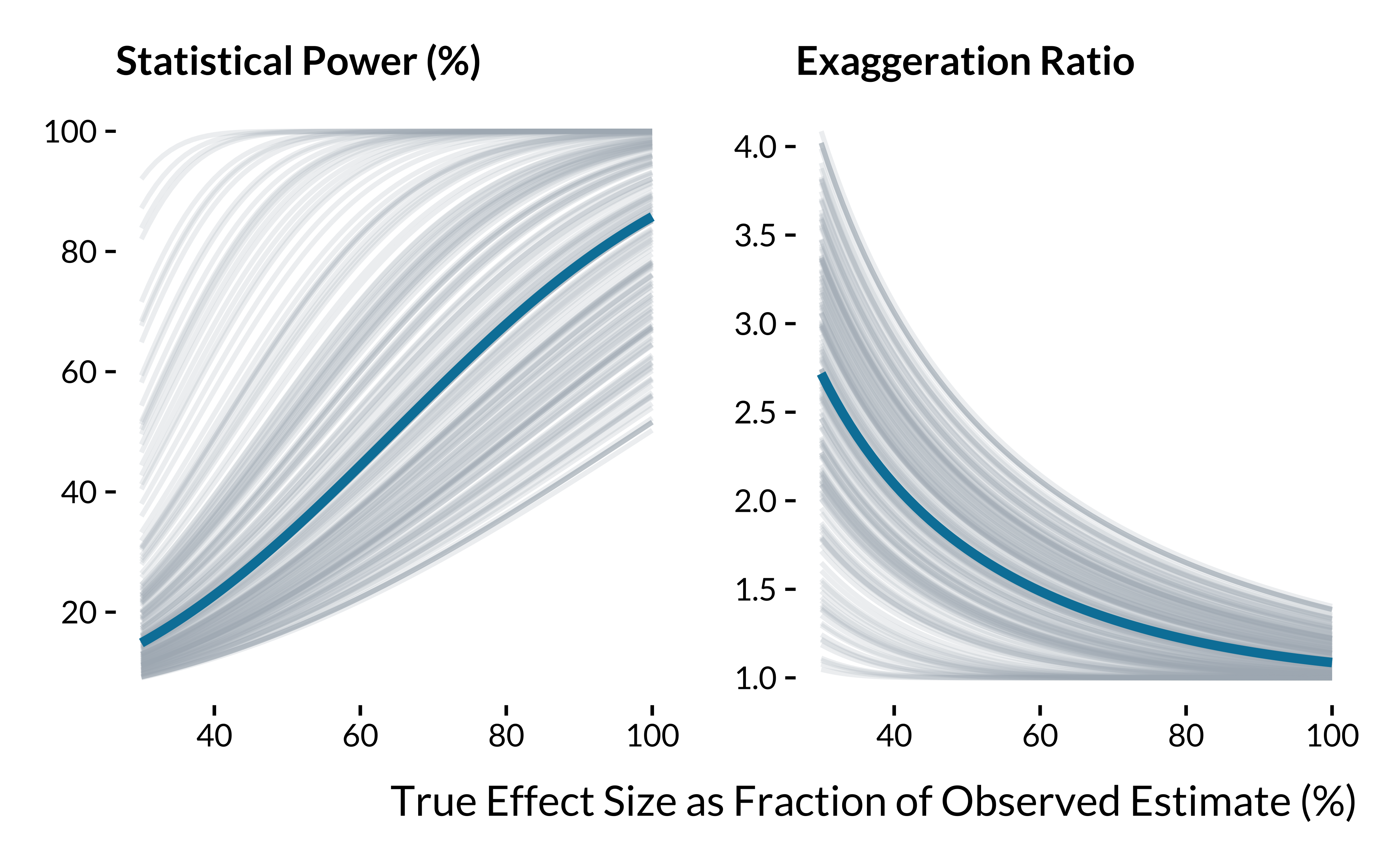
We display below summary statistics for the scenario where true effect sizes are equal to the observed estimates reduced by 25%:
Show code
data_retrodesign_fraction %>%
filter(percentage == 0.75) %>%
group_by(metric) %>%
summarise(
"Min" = min(value, na.rm = TRUE),
"First Quartile" = quantile(value, na.rm = TRUE)[2],
"Mean" = mean(value, na.rm = TRUE),
"Median" = median(value, na.rm = TRUE),
"Third Quartile" = quantile(value, na.rm = TRUE)[4],
"Maximum" = max(value, na.rm = TRUE)
) %>%
mutate_at(vars(-metric), ~ round(., 1)) %>%
rename(Metric = metric) %>%
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")| Metric | Min | First Quartile | Mean | Median | Third Quartile | Maximum |
|---|---|---|---|---|---|---|
| Exaggeration Ratio | 1.0 | 1.1 | 1.3 | 1.3 | 1.5 | 1.8 |
| Statistical Power (%) | 31.4 | 46.2 | 65.5 | 62.3 | 85.0 | 100.0 |
| Type S Error (%) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
And here when estimates are divided by two:
Show code
data_retrodesign_fraction %>%
filter(percentage == 0.5) %>%
group_by(metric) %>%
summarise(
"Min" = min(value, na.rm = TRUE),
"First Quartile" = quantile(value, na.rm = TRUE)[2],
"Mean" = mean(value, na.rm = TRUE),
"Median" = median(value, na.rm = TRUE),
"Third Quartile" = quantile(value, na.rm = TRUE)[4],
"Maximum" = max(value, na.rm = TRUE)
) %>%
mutate_at(vars(-metric), ~ round(., 1)) %>%
rename(Metric = metric) %>%
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")| Metric | Min | First Quartile | Mean | Median | Third Quartile | Maximum |
|---|---|---|---|---|---|---|
| Exaggeration Ratio | 1.0 | 1.4 | 1.7 | 1.7 | 2.0 | 2.5 |
| Statistical Power (%) | 16.6 | 23.7 | 41.3 | 32.9 | 51.5 | 100.0 |
| Type S Error (%) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
OLS Estimates as True Effect Sizes
For statistically significant 2SLS estimates, we define the true values of effect size as the corresponding OLS estimates. We assume that (i) the causal estimand targeted by the naive and instrumental variable strategy is the same (i.e., we are in the case of homogeneous constant treatment effects), (ii) that there are no omitted variables and (iii) no classical measurement errors in the air pollution exposure.
We retrieve 98 2SLS estimates that were statistically significant at the 5% level and had
Show code
# retrieve iv data
data_iv <- data_lit_causal_std %>%
select(
paper_label,
empirical_strategy,
outcome,
independent_variable,
estimate,
standard_error
) %>%
filter(empirical_strategy == "instrumental variable") %>%
filter(abs(estimate / standard_error) >= 1.96) %>%
select(-empirical_strategy)
# retrieve ols data
data_ols <- data_lit_causal_std %>%
select(paper_label,
empirical_strategy,
outcome,
independent_variable,
estimate,
standard_error) %>%
filter(empirical_strategy == "conventional time series") %>%
select(-empirical_strategy) %>%
rename(estimate_ols = estimate, standard_error_ols = standard_error)
# merge the two datasets
data_iv_ols <-
left_join(data_iv,
data_ols,
by = c("paper_label", "outcome", "independent_variable")) %>%
drop_na(estimate_ols)
# compute power, exaggeration and s errors
data_retro_iv <- data_iv_ols |>
mutate(
retro = map2(estimate_ols, standard_error,
\(x, y) retro_design_closed_form(x, y))
#retro_design returns a list with power, type_s, type_m
) |>
unnest_wider(retro) |>
mutate(power = power * 100, type_s = type_s * 100) |>
mutate_at(vars(power, type_m), ~ round(., 1)) %>%
select(-estimate, -standard_error, -estimate_ols) %>%
pivot_longer(
cols = c("power", "type_m"),
names_to = "metric",
values_to = "value"
) %>%
mutate(metric = ifelse(
metric == "power",
"Statistical Power (%)",
"Exaggeration Ratio"
))
prop_adequate <- data_retro_iv |>
filter(str_starts(metric, "Stat")) |>
count(prop_adequate = sum(value > 80)/n()) |>
pull(prop_adequate)
# compute summary stats
summary_retro_iv <- data_retro_iv %>%
group_by(metric) %>%
summarise(median = median(value))
# graph power
graph_retro_iv_power <- data_retro_iv %>%
filter(metric == "Statistical Power (%)") %>%
ggplot() +
geom_linerange(aes(x = value, ymin = -0.5, ymax = 0.5),
colour = "#0081a7",
alpha = 0.6) +
geom_linerange(
data = summary_retro_iv,
aes(x = median[2], ymin = -0.5, ymax = 0.5),
size = 1.1,
colour = "#f07167"
) +
# annotate(geom = "label", x = 13.5, y = 0.27, label = "Median", colour = "#f07167", fill="white", label.size = NA, label.r=unit(0, "cm"), size = 6) +
# geom_curve(aes(x = 14.5, y = 0.10,
# xend = 8.8, yend = -0.2),
# curvature = -0.3,
# arrow = arrow(length = unit(0.42, "cm")),
# colour = "#f07167",
# lineend = "round") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 10)) +
expand_limits(x = 0, y = 0) +
labs(x = "Power (%)", y = NULL, title = "Distribution of Statistical Power") +
theme(
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
panel.grid.major.y = element_blank()
)
# graph exaggeration error
graph_retro_iv_exagg <- data_retro_iv %>%
filter(metric == "Exaggeration Ratio") %>%
filter(value < 42) %>%
ggplot() +
geom_linerange(aes(x = value, ymin = -0.5, ymax = 0.5),
colour = "#0081a7",
alpha = 0.8) +
geom_linerange(
data = summary_retro_iv,
aes(x = median[1], ymin = -0.5, ymax = 0.5),
size = 1.1,
colour = "#f07167"
) +
expand_limits(x = 1, y = 0) +
labs(x = "Exaggeration Factor", y = NULL, title = "Distribution of Exaggeration Factor") +
theme(
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
panel.grid.major.y = element_blank()
)
# combine graphs
graph_retro_iv <- graph_retro_iv_power / graph_retro_iv_exagg
# save graph
ggsave(
graph_retro_iv,
plot_annotation +
theme(plot.title = element_blank(),
plot.subtitle = element_blank()),
filename = here::here(
"images",
"graph_retro_iv.pdf"
),
width = 30,
height = 15,
units = "cm"
# device = cairo_pdf
)
# display the graph
graph_retro_iv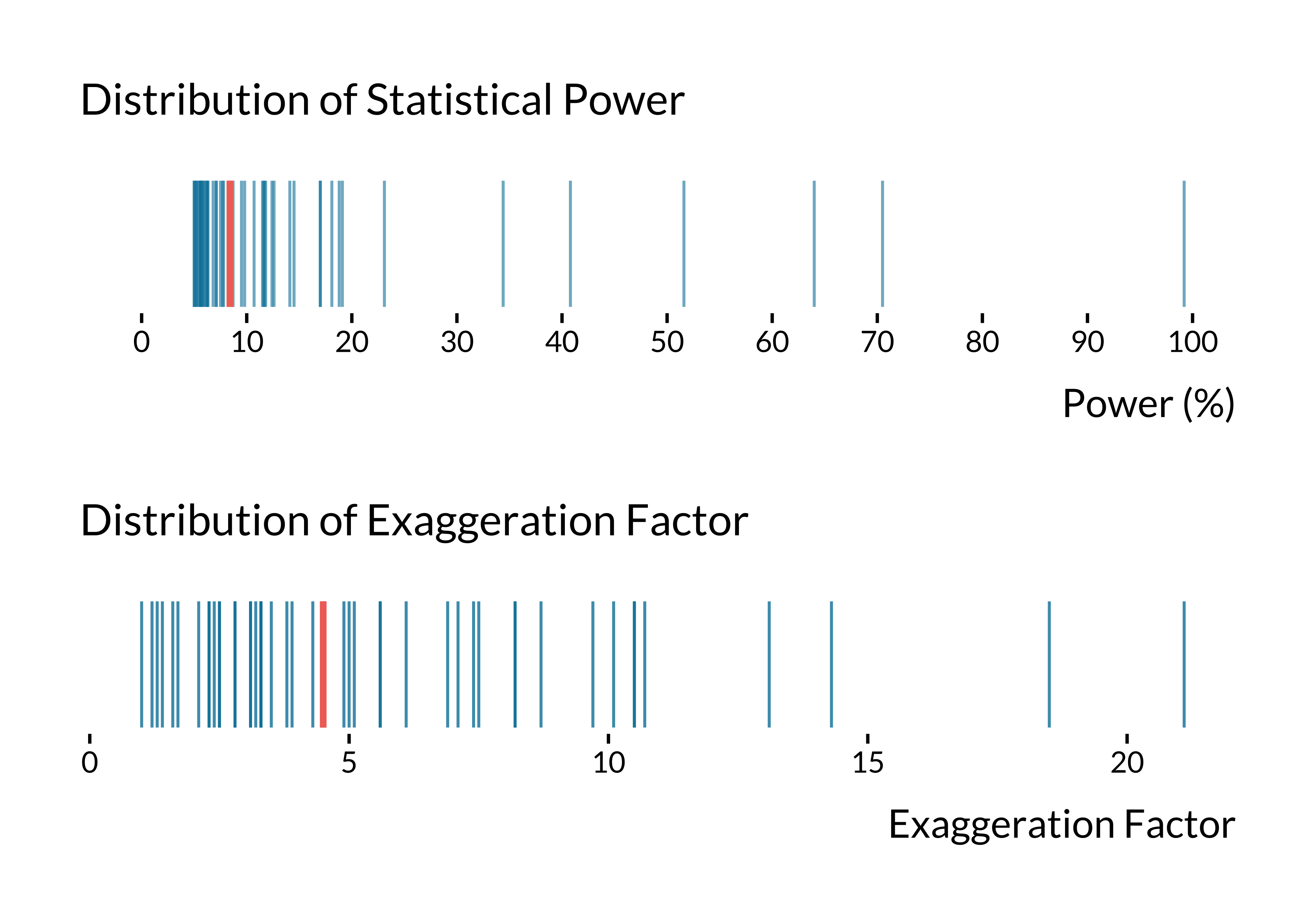
The median statistical power is 8.4% and the median exaggeration ratio is 4.5. 2.04% of IV designs have adequate power (i.e. greater than 80%).