Abstract
The credibility revolution has made causal inference methods ubiquitous in economics. Yet there is widespread evidence of selection on statistical significance and associated biases in the literature. I show that these two phenomena interact to reduce the reliability of published estimates: while causal identification strategies alleviate bias from confounders, by restricting the variation used for identification they reduce statistical power and can exacerbate another bias–exaggeration. I characterize this confounding-exaggeration trade-off theoretically and through realistic Monte Carlo simulations, and explore its prevalence in the literature. In realistic settings, exaggeration can exceed the confounding bias these methods aim to eliminate. Finally, I propose practical solutions to navigate this trade-off, including a versatile tool to identify the variation and observations actually driving identification in applied causal studies.
Non-technical summary
In this paper, I show that front-line empirical methods used in economics, while useful and effective to evaluate how a factor causes another, might in some cases lead to concluding that effects are larger than they actually are when combined with current academic publication practices.
Empirical studies often aim to get a sense of how a factor causes another. For instance, one may want to evaluate the impact of a professional training program on wages. Such effects are often challenging to estimate. A simple difference between the wages of people who participated or not in the program may not reflect the actual wage increase brought by the program; people who took part in the program might have earned higher wages even if they had not received the training. To measure the actual magnitude of the effect of the program, researchers use a particular set of methods. These methods, while convincing, may be imprecise. They can produce a rather wide range of plausible magnitudes for the effect of the program. If one could reproduce the analysis many times, on average, one would get to the true effect of this training program. Yet, for cost reasons, analyses are often only carried out once. The lack of precision of the methods means that a particular study can produce results that are quite far from the true effect.
On the other hand, previous research has shown that publication practices favor results that seem ostensibly non-null; that is to say far from zero. Now, if the true effect is small and the study imprecise, the published result will not only be far from zero but also far from the true effect.
The set of methods mentioned above enables to convincingly measure how a factor causes another. However, in this paper, I show that these methods are also more subject to the publication issue described above. In some cases, they may be more likely than conventional methods to produce effect sizes that are too large. I demonstrate that there is a trade-off between measuring an actual causal impact and exaggerating effect sizes as a result of the publication problem discussed above.
To do so, I first illustrate the importance of this trade-off by reviewing several subsets of the economics literature. To study the mechanisms driving this trade-off more precisely, I build simulations, generating fake data representative of real-life situations. I have to rely on simulations because to evaluate how far the result of an analysis is from the true effect, one needs to know this true effect. In real-life cases, the true effect is never known (otherwise one would not build a study to estimate it). Simulations enable me to define a fake “true effect” myself and to vary parameters to explore the drivers of the trade-off considered. I also derive a formal mathematical proof of the existence of the trade-off described above and of the impact of its drivers.
To conclude, I discuss practical solutions to avoid exaggerating true effect sizes. Computing and reporting simple power calculations can help evaluate the risk of exaggeration. I also develop a tool—an R software package called ididvar—to help researchers gauge where their study lies with respect to this trade-off and to assess potential exaggeration risks.
A social network summary
Post 1/N
I updated my working paper showing that causal inference methods induce a trade of between confoundings and exaggerating true effect sizes.
By limiting the variation used for identification, they reduce statistical power and precision and can exacerbate another bias, exaggeration.

Post 2/N
When power is low, the distribution of estimates is spread out. Only estimates that are 1.96 sd away from 0 are statistically significant.
With low statistical power, significant estimates are always exaggerated.
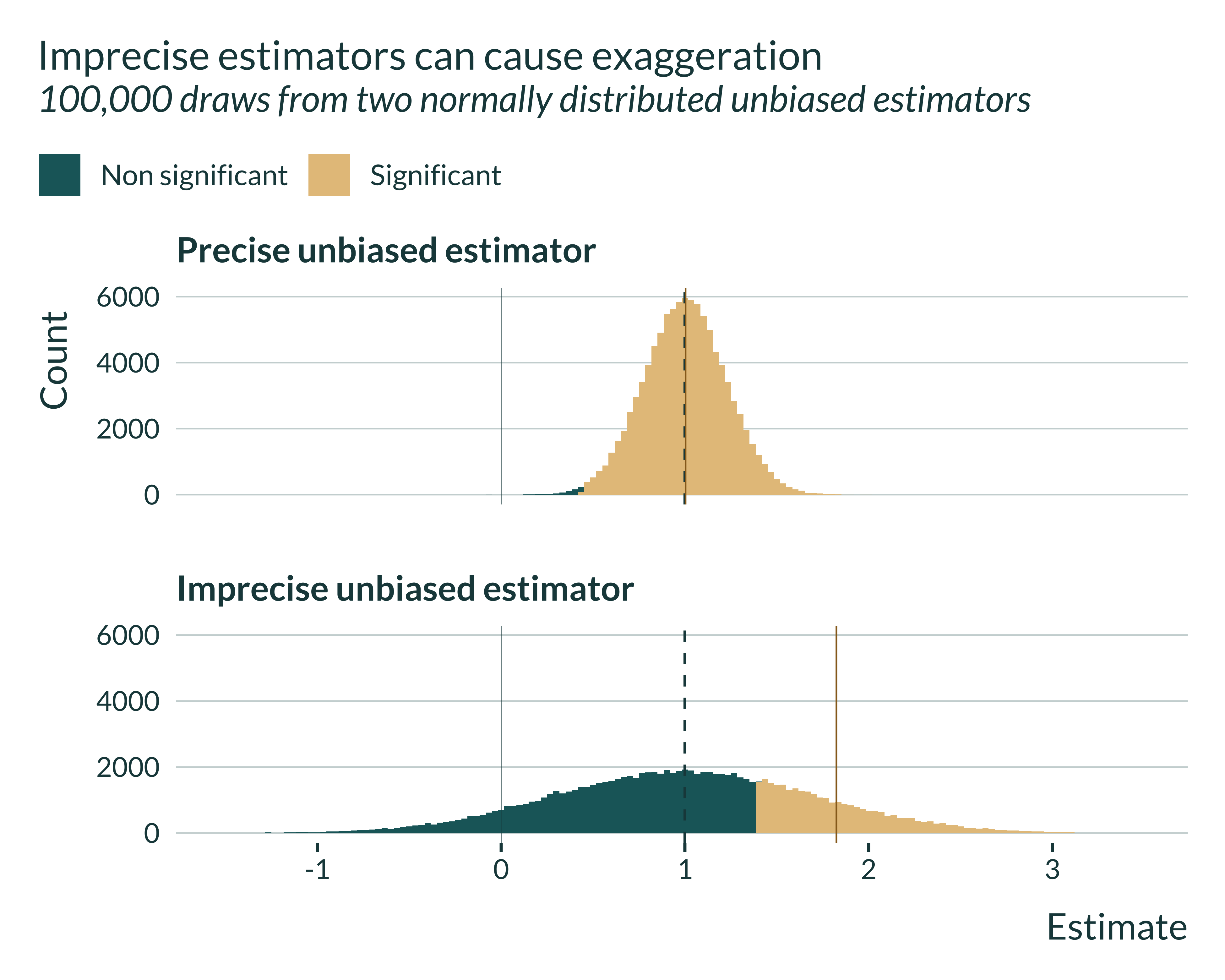
Post 3/N
Causal id strat reduce power because they throw out part of the variation. Using too little variation can create an exaggeration bias, even if this variation is exogenous.
I characterize this trade-off theoretically and through realistic MC simulations, and explore its prevalence in the literature
Post 4/N
Consequential exaggeration has been documented in econ (often by a factor 2 to 4). Its two ingredients, present in the lit, are selection on significance and lack of statistical power.
I highlight a mechanism explaining exaggeration despite our extensive use of convincing causal inference methods.
Post 5/N
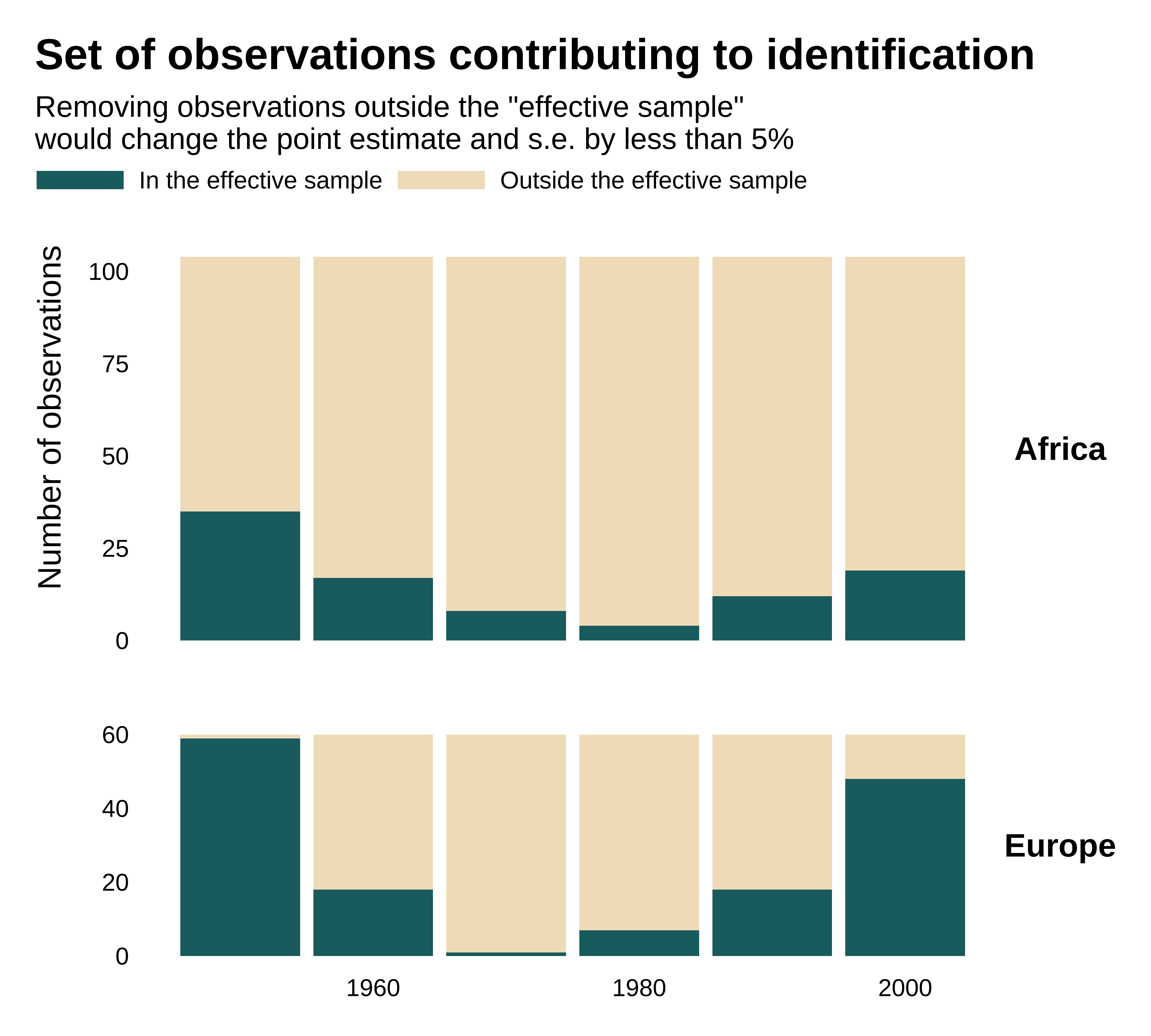
RDD discards variation by only considering observations within the bandwidth. It decreases the effective sample size.
On average significant estimates may never get close to the true effect.
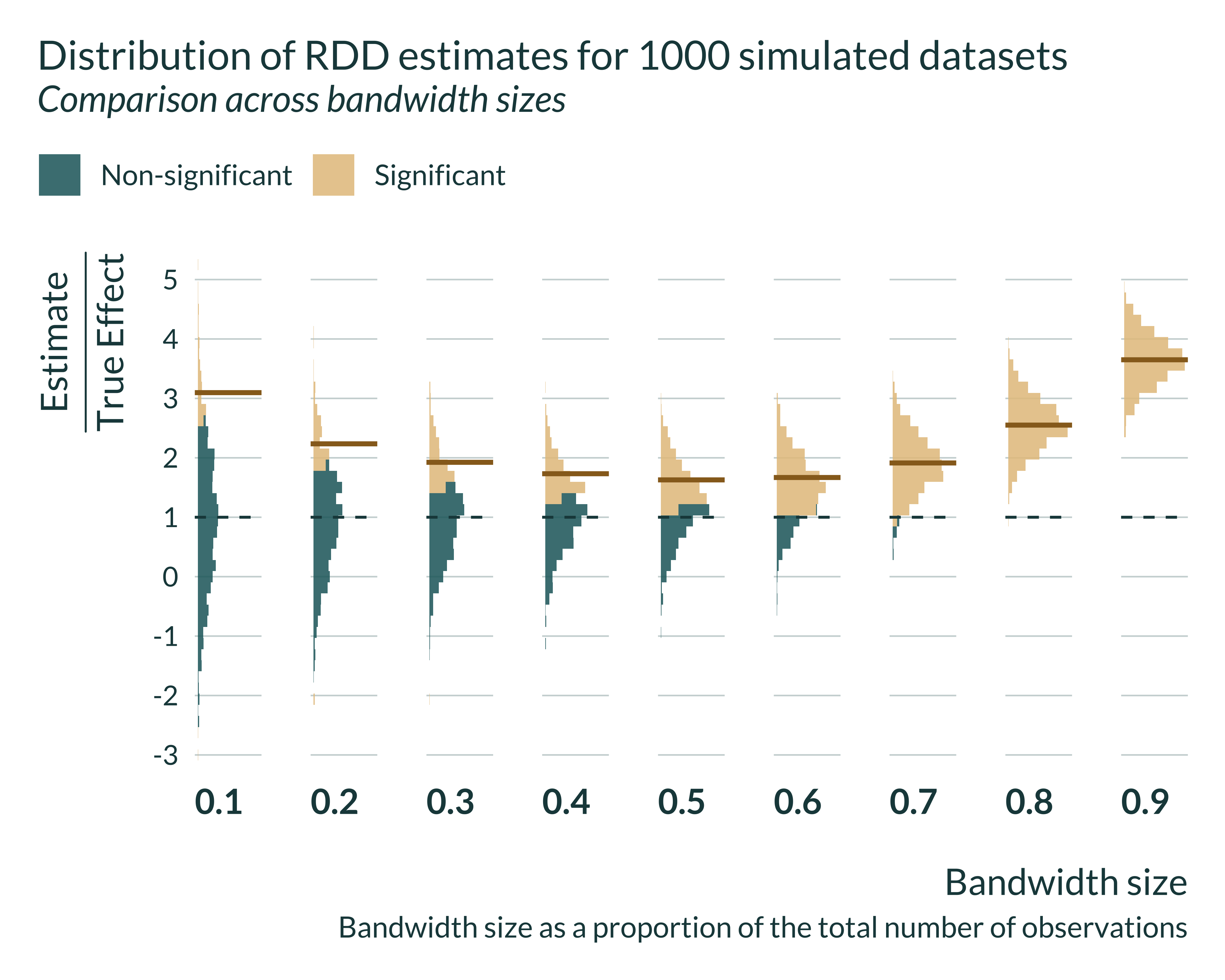
Post 6/N
IV only uses part of the variation in the treatment, the portion explained by the instrument. When the “strength” of the instrument is low, the IV is imprecise and can induce exaggeration.
A “naive” OLS can, on average, produce significant estimates that are closer to the true effect than the IV.
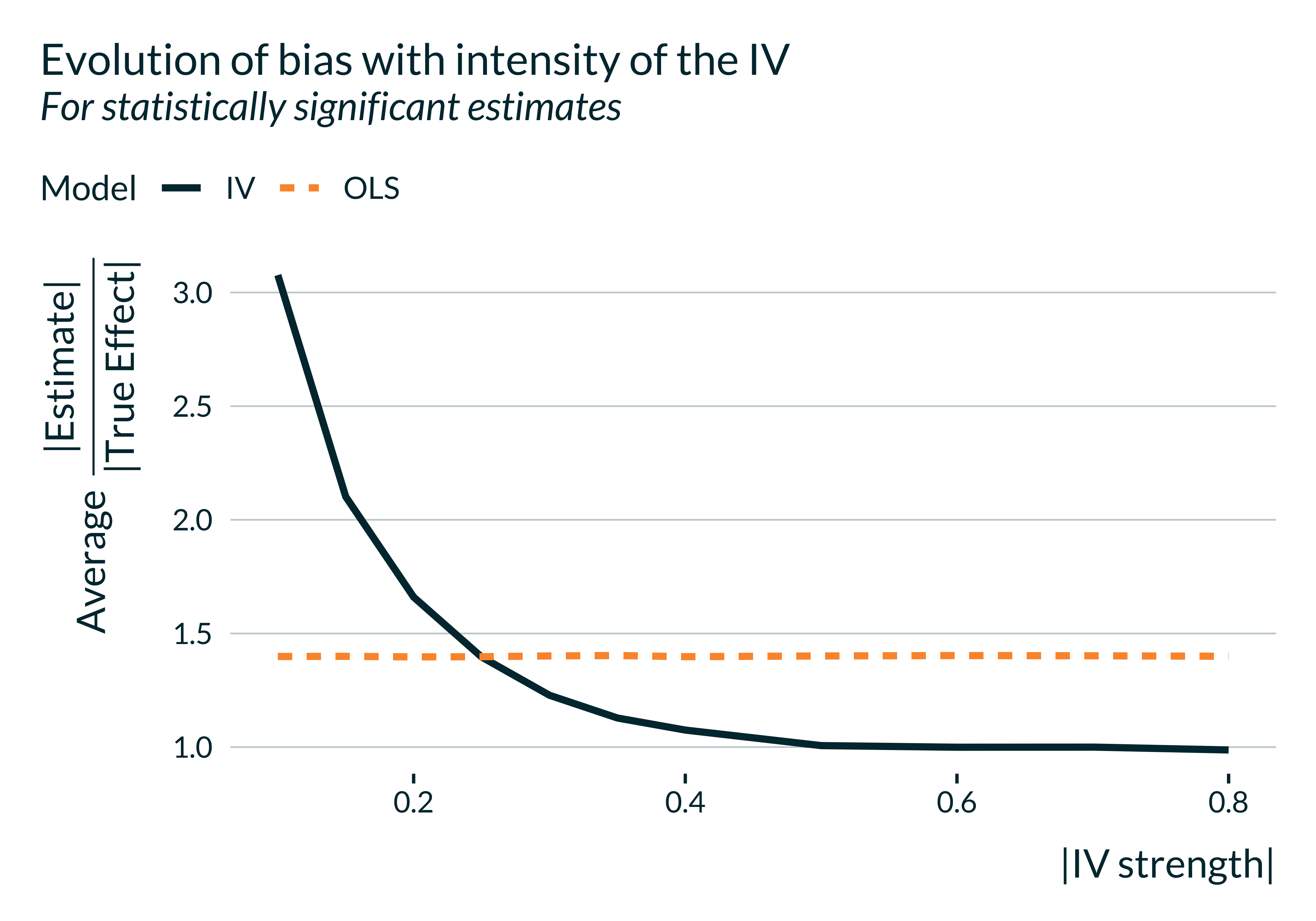
Post 7/N
When leveraging exogenous shocks, the variation sometimes only comes from a limited number of treated observations. Power can thus be low and estimates inflated.
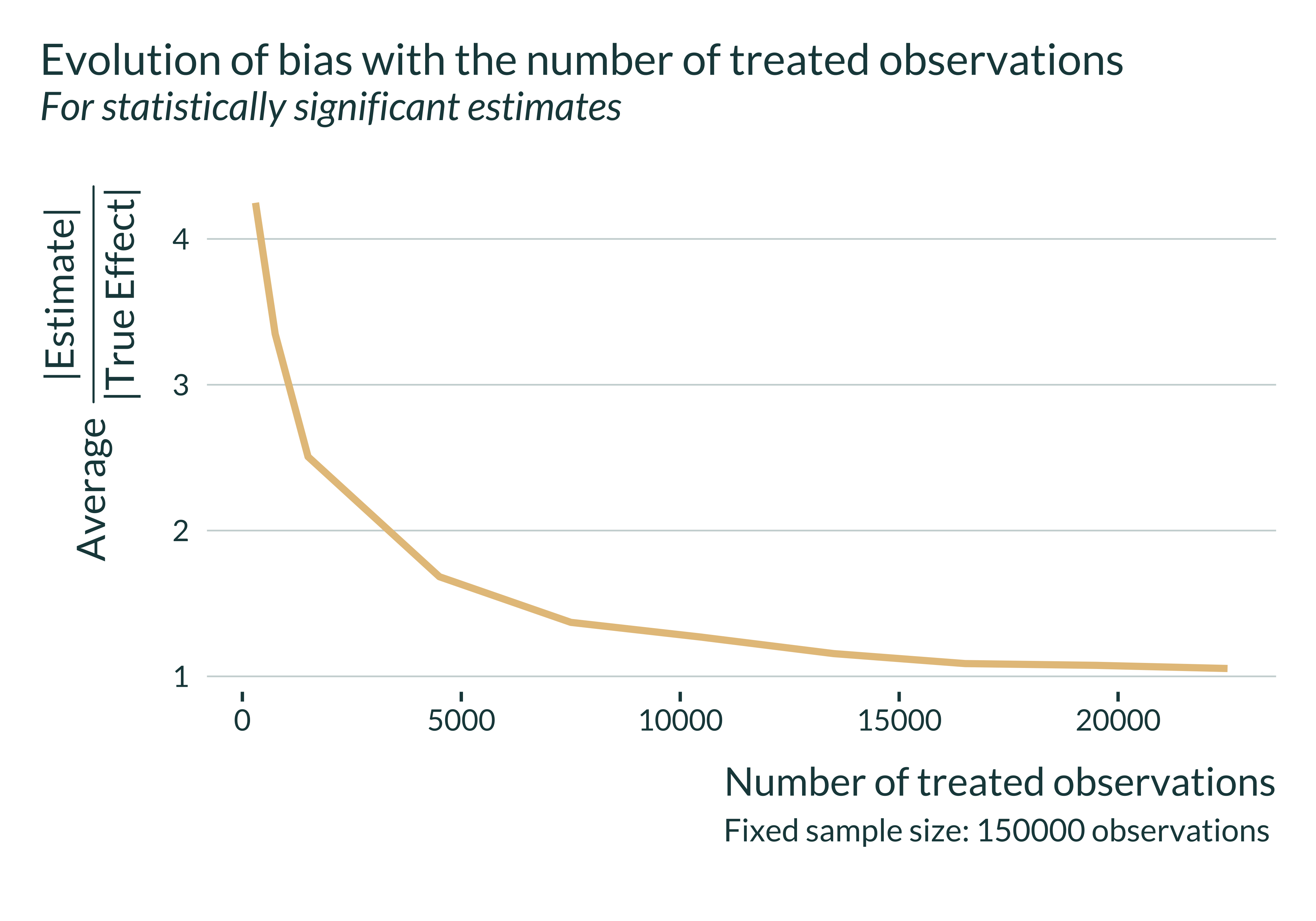
Post 8/N
If fixed effects or controls absorb a lot of the variation in X (more than in Y), the resulting identifying variation might be limited, leading to imprecision and exaggeration.
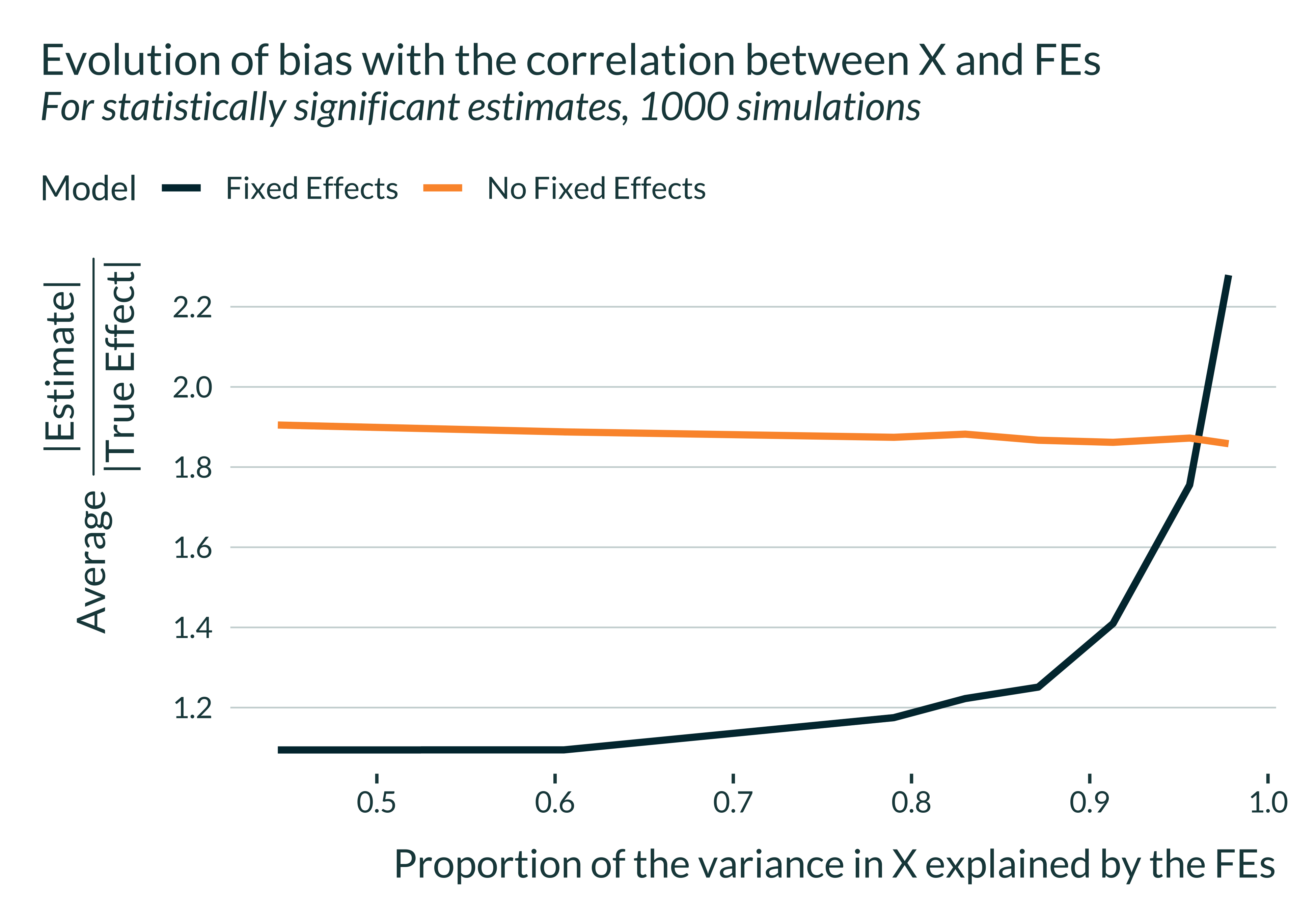

Post 9/N
A systematic reporting of pre and post analysis power calculations in observational studies would help gauge the risk of falling into this low power trap.
The confounding-exaggeration trade-off is mediated by the variation used for identification, I provide tools to explore it.
Post 10/N
I developed a R package, ididvar, that provides tools to easily identify the identifying variation in a regression: vincentbagilet.github.io/ididvar/
The following vignette introduces in details: vincentbagilet.github.io/causal_exaggeration/ididvar.html
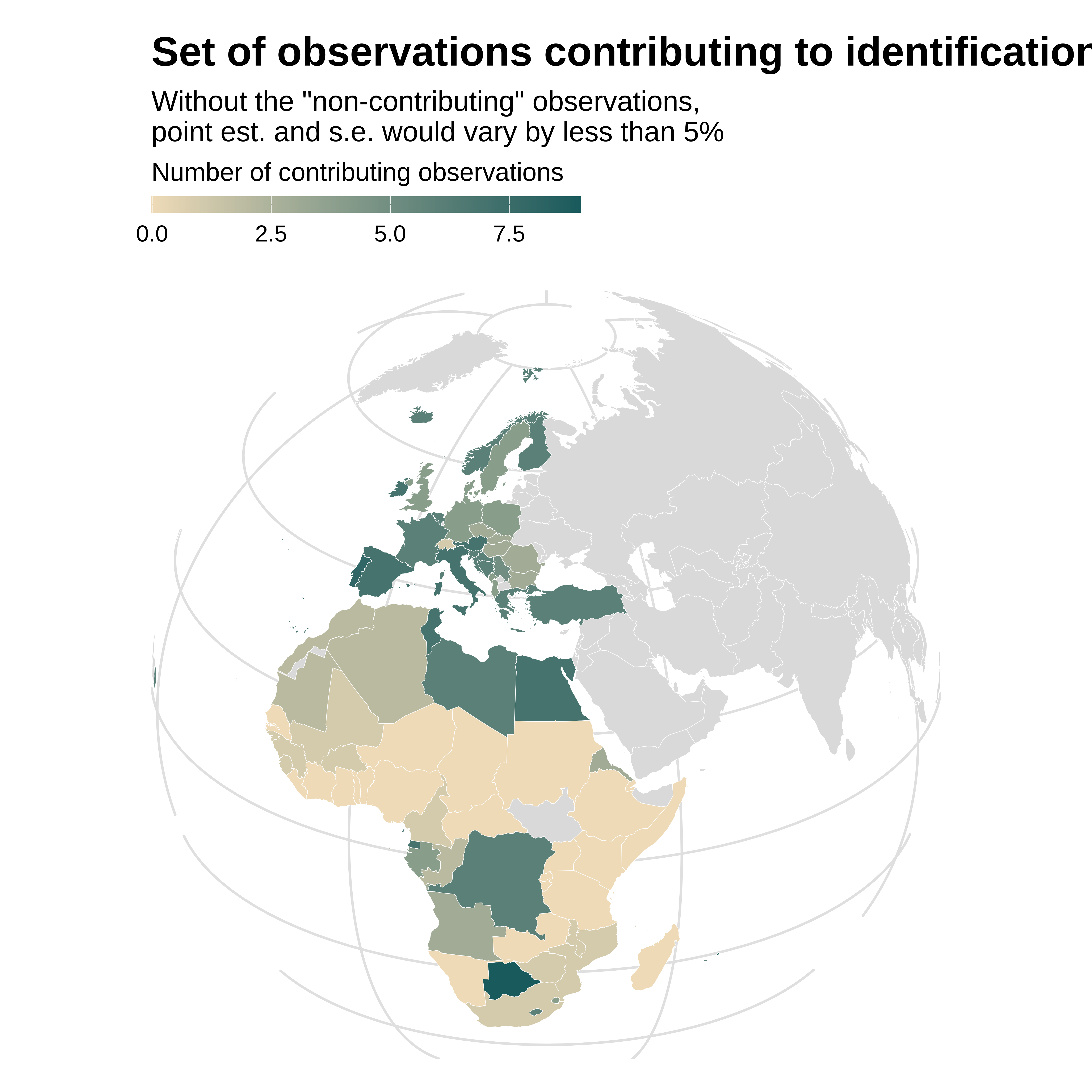
Post 11/N
ididvar computes identifying variation weights as the leverage of each observation but after having partialled out the controls (including those identification-related) and FE.
Some observations do not contribute to identification and dropping them would not change the estimate.
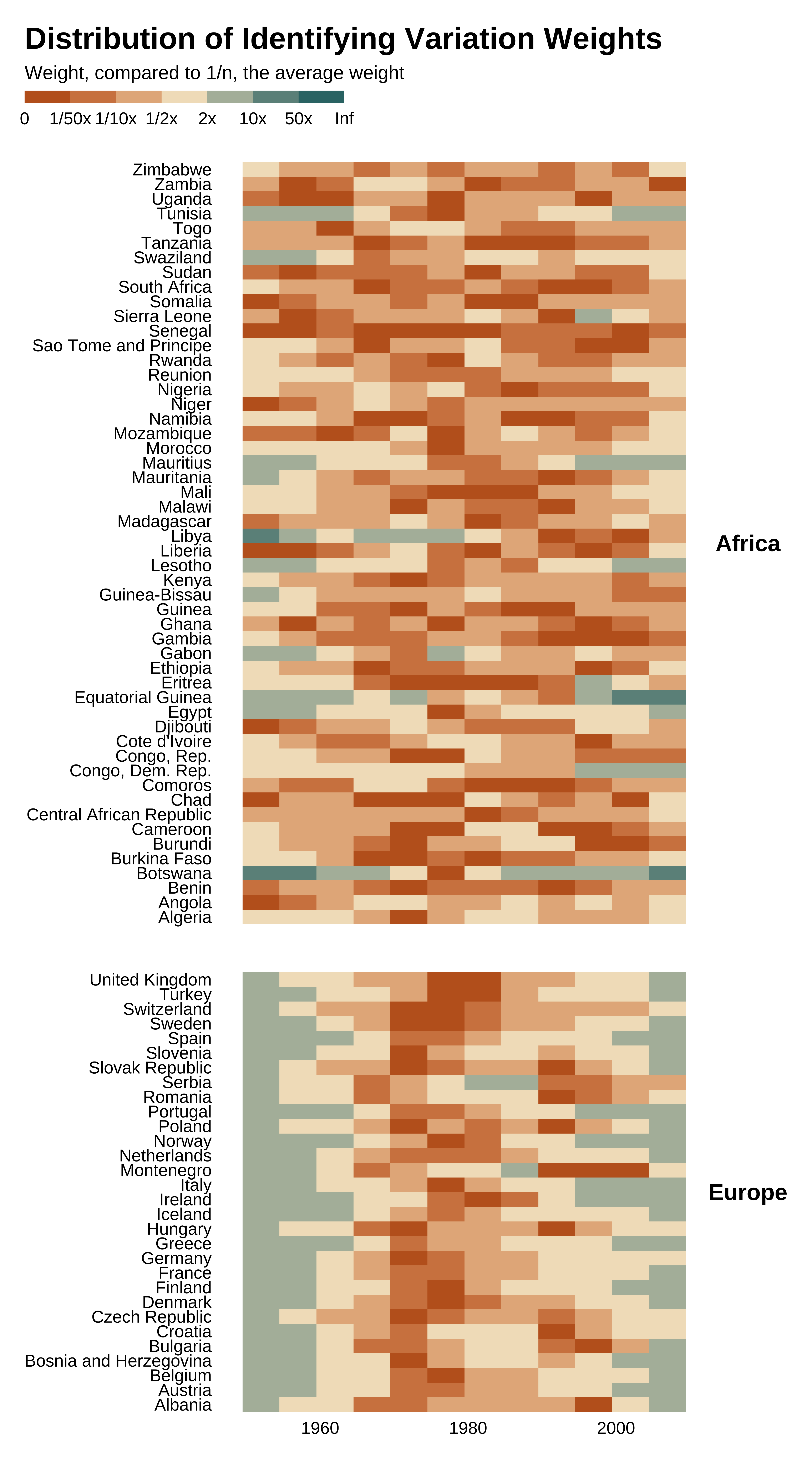
Post N/N
The paper summed up in a few pictures:
