What is exaggeration?
Exaggeration is one of the key concepts in the present paper. To understand how low statistical power can cause exaggeration in the presence of publication bias, let’s analyze replications of laboratory experiments in economics ran by Camerer et al. (2016).1
First, I retrieve their replication results, alongside the results of the initial studies, from their project website. I just ran their Stata script create_studydetails.do to generate their data set. Since the standard errors of the estimates are not reported in this data set, I recompute them.
First, I focus on one particular study, Abeler et al. (2011), in order to illustrate in more details the issue of interest. I first plot in red the estimate and 95% confidence intervals Abeler et al. (2011) obtained in their experiment (note that I will run replications and there will be several draws of estimates in subsequent graphs, hence why the x-axis of the graph below):
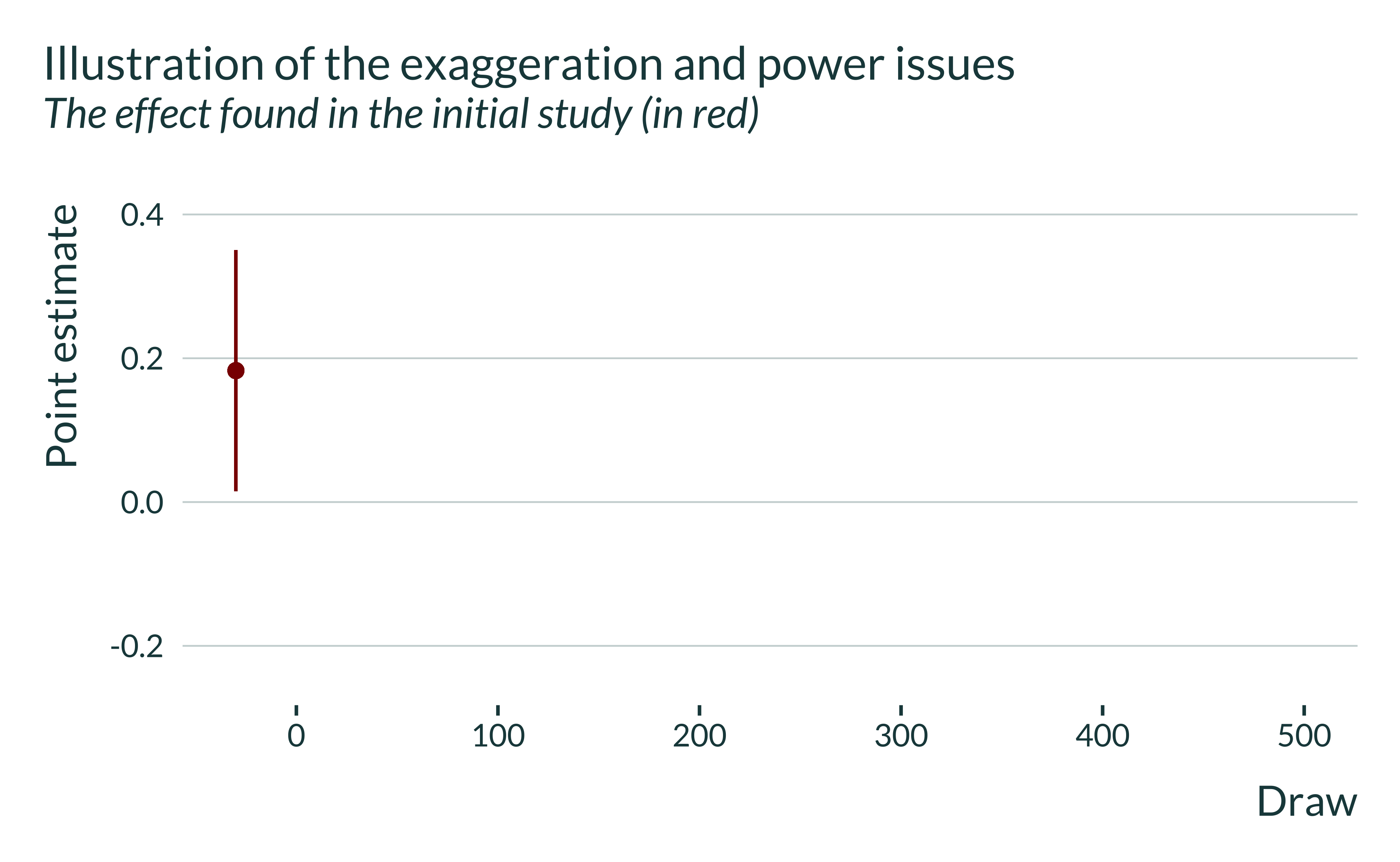
This estimate is significant and has been published. Yet, it is pretty noisy.
I then plot the result of the replication in blue:
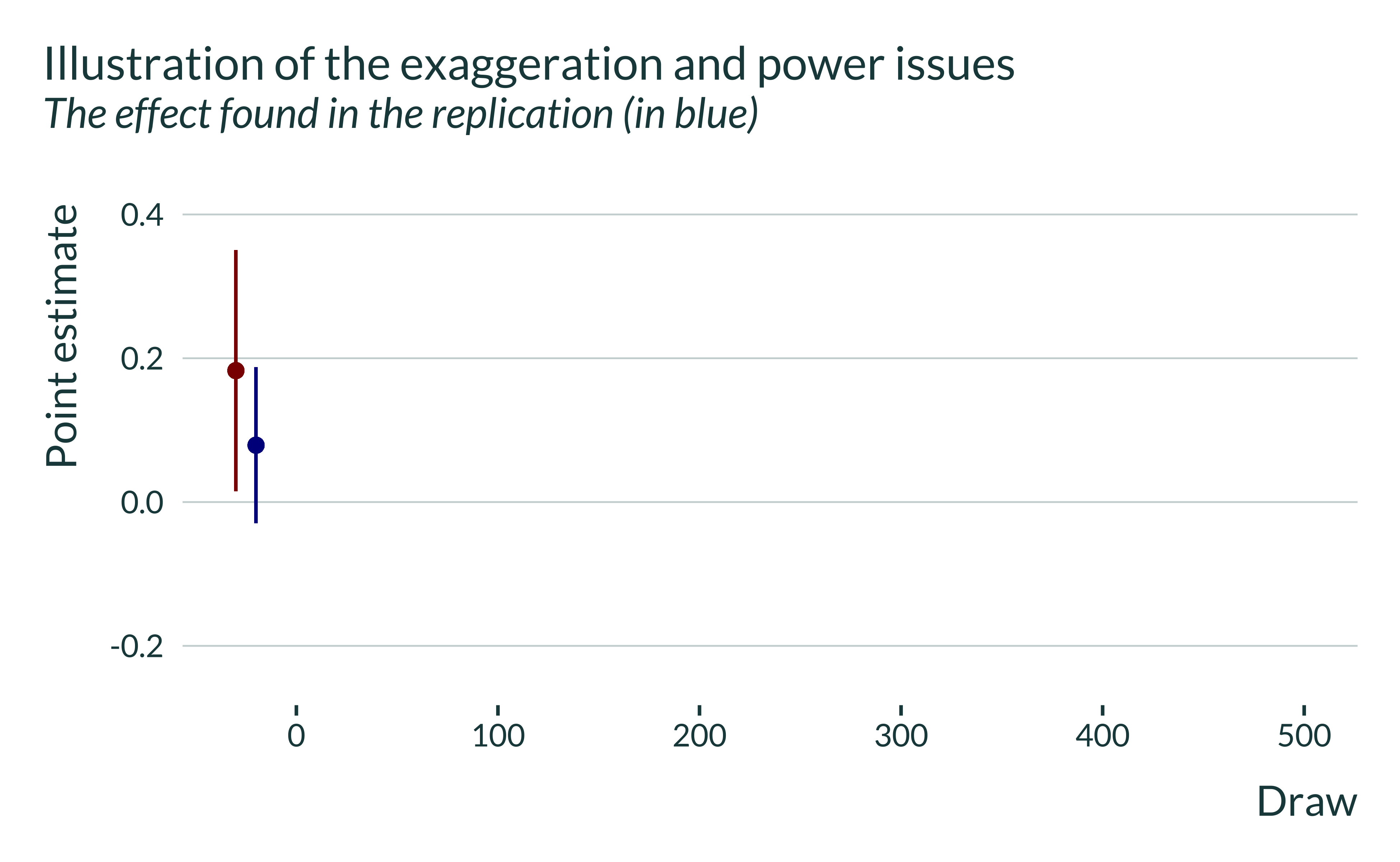
This estimate is both more precise and smaller than the initial one. It still remains noisy and it is not statistically significant.
Let’s now assume that the true effect is actually equal to this replicated estimate. Would the design of the initial study be good enough to detect this effect? ie if we replicated the initial study, could we reject the null of no effect, knowing that the true effect is equal to the replicated estimate?
To illustrate this, I first plot in gray the point estimate form the replicated study but with a standard error equal to the initial study’s, i.e. approximately the estimate that would have been obtained with the design of the initial study but with an effect equal to the replicated one. This emulates what would have yielded a replication of the initial study if the true effect was equal to the replication estimate.
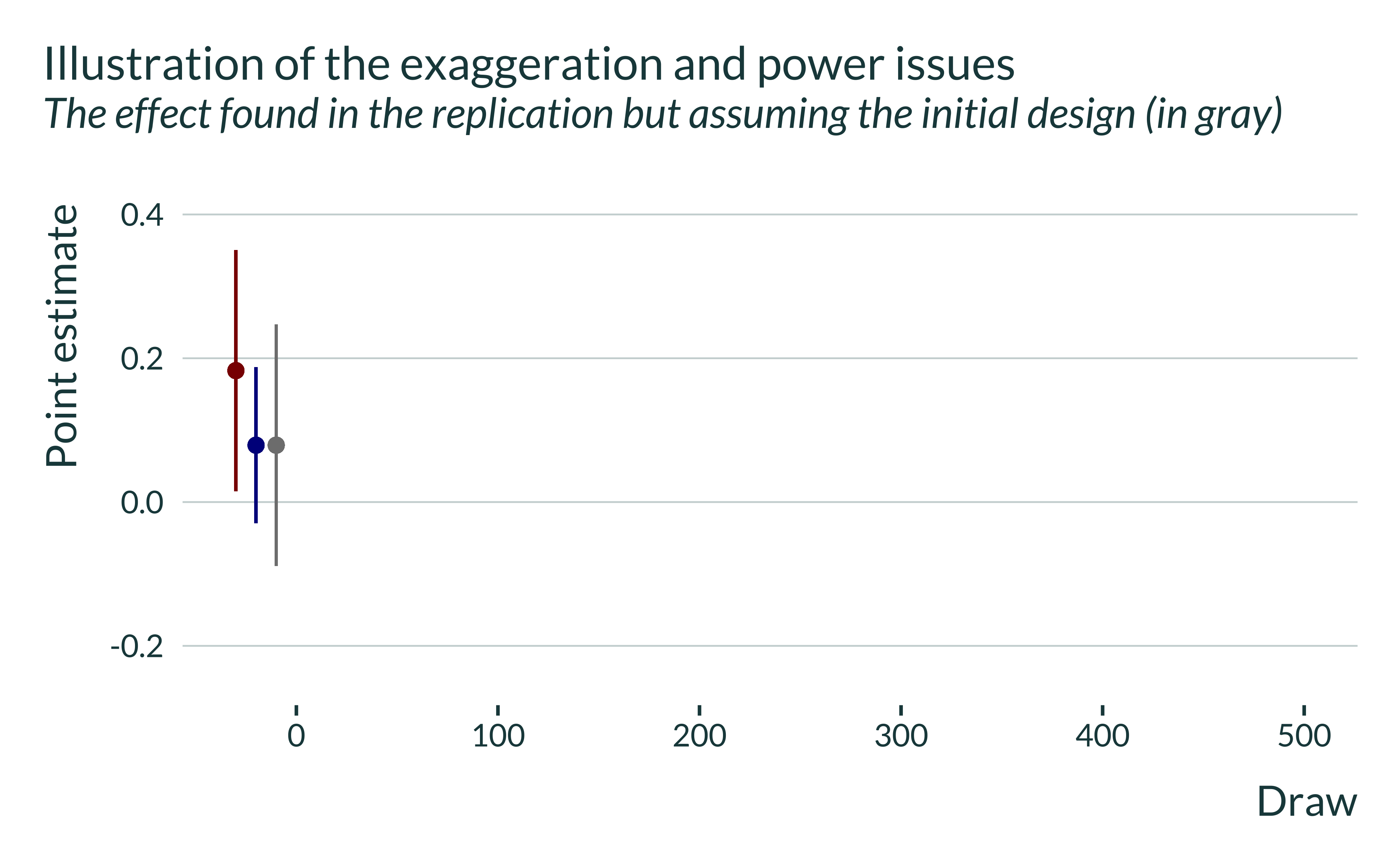
This estimate is non significant. In this instance, we would not have been able to reject the null of no effect. Now, let’s replicate this study 500 times, running 500 lab experiments with the design of the initial study and under the assumption of a true effect equal to the one obtained in the replication:
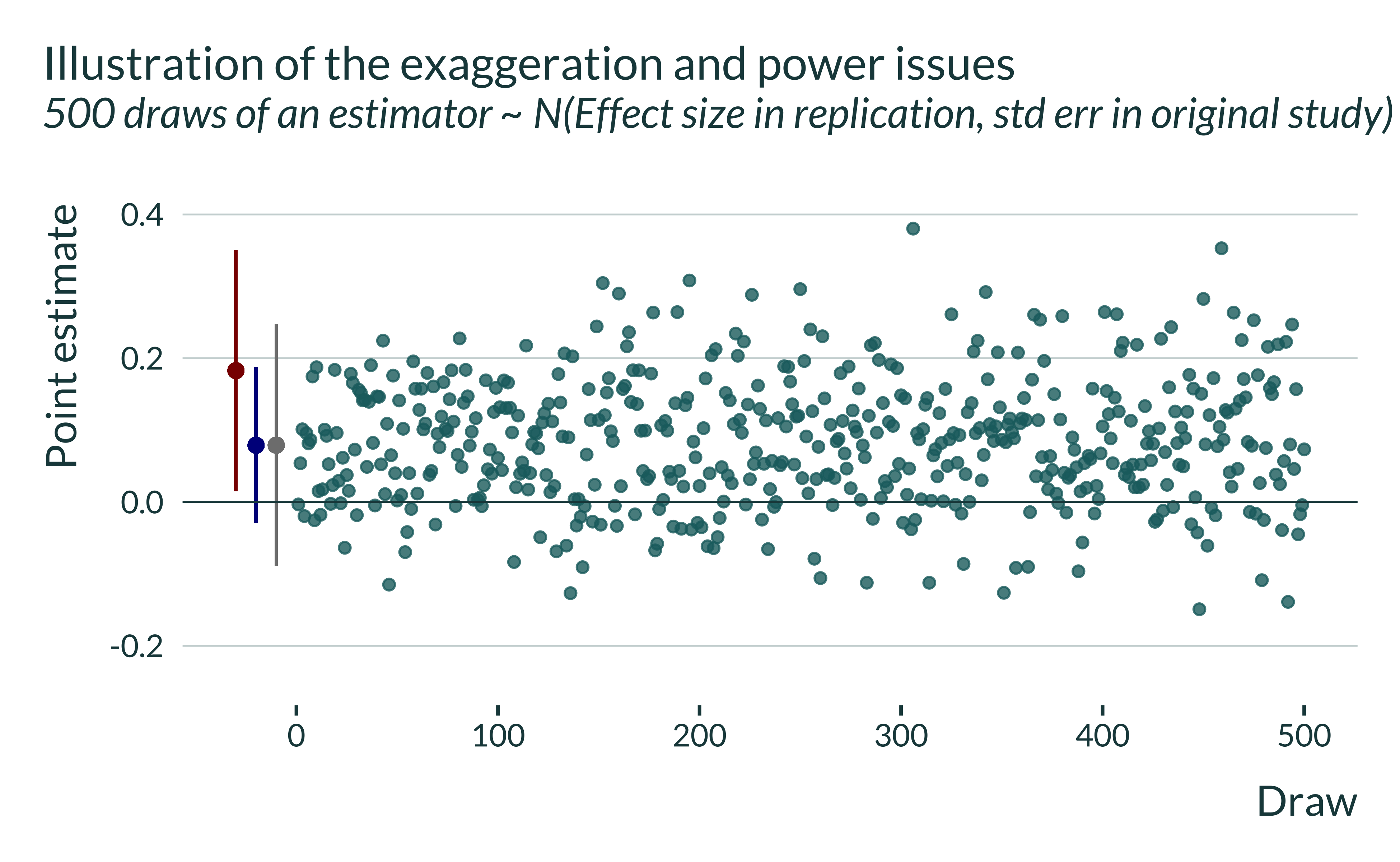
The distribution is centered on the “true effect” (i.e., the point estimate found in the replication study) and has a standard deviation equal to the standard error of the estimator of the original study. Let’s now condition on statistically significance:
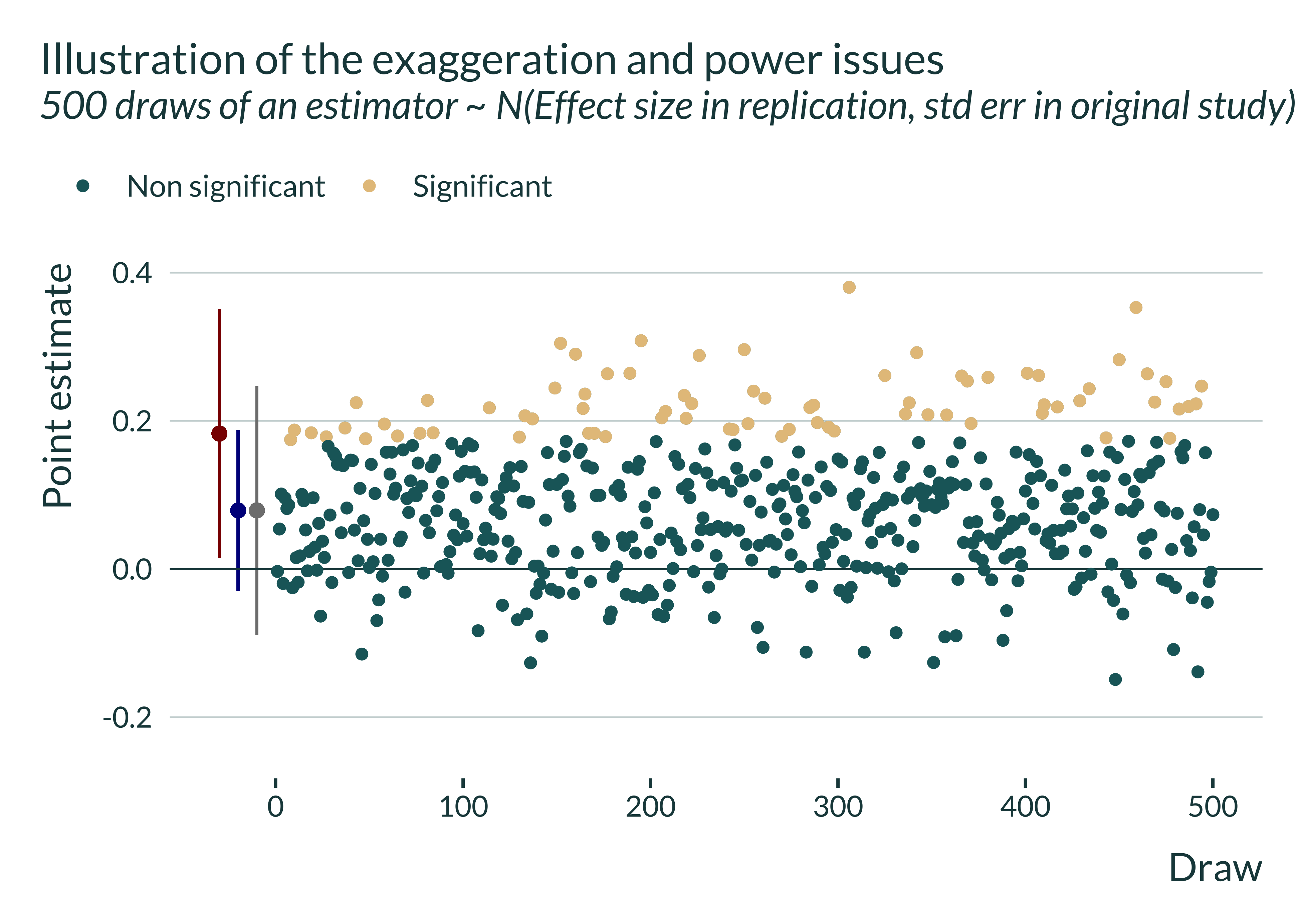
In some cases we would get statistically significant estimates (the beige dots) and non statistically significant ones (the green dots) in others cases. The statistical power here is basically the proportion of statistically significant estimates.
Zooming in on the first draws and plotting their 95% confidence intervals (approximately \([\hat{\beta} - 1.96 \cdot \sigma_{\hat{\beta}}, \hat{\beta} + 1.96 \cdot \sigma_{\hat{\beta}}]\)) helps understand why some estimates are deemed significant and not others. By definition, significant estimates are those whose confidence interval does not contain 0:
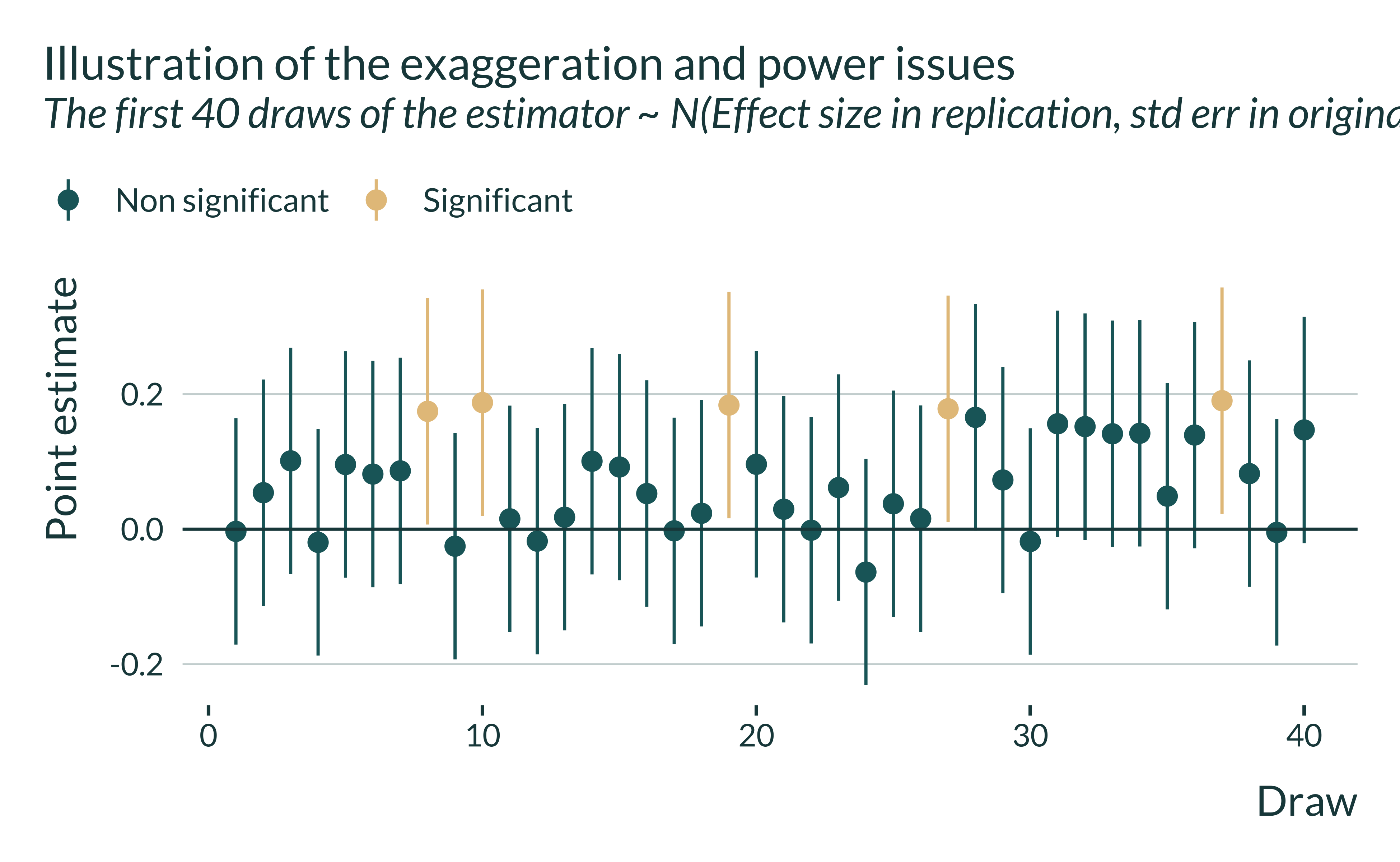
If the study was more precise, the standard error of the estimator would be smaller and more estimates would be statistically significant. The study would have more statistical power. But since the power is low here (or equivalently since the estimator is relatively imprecise), statistically significant estimates only represent a subset of the estimate and on average overestimate the true effect. They overestimate it by a factor 2.85 (average of 0.23 while the true effect is 0.079).
On average, statistically significant estimates overestimate true effect sizes when statistical power is low.
Do we actually see exaggeration in the literature?
Evidence of consequential exaggeration in the literature as been established by previous studies:
- Ioannidis, Stanley, and Doucouliagos (2017) finds that nearly 80% of estimates in a wide range of areas in economics are likely exaggerated by a factor of two. They use meta-analyses to compute the statistical power of published studies.
- Ferraro and Shukla (2020) estimates that 56% of results in environmental economics are exaggerated by a factor of two or more. They use a methodology close to Ioannidis, Stanley, and Doucouliagos (2017) (but slightly more conservative).
- DellaVigna and Linos (2022) shows that, due to exaggeration, academic papers on nudge experiments find results that are typically 6 times larger than in large-scale experiments
- Arel-Bundock et al. (2024) finds that estimates in the political science are about 3 times too large.
I further investigate this question for a set of different literatures:
- Studies from top economics journals,
- IV studies published in top economics journals,
- An example literature, that on the short-term health effects of air pollution that I further explore in a companion paper (Bagilet 2023)
- The experimental literature
I begin by examining broad literatures that require strong assumptions about true effect sizes, then progressively narrow my focus to more specific literatures that allow me to relax these assumptions. I find heterogeneity across studies: while exaggeration might be limited in some analyses, it is likely substantial in many others.
Why does imprecision lead to exaggeration?
The confounding / exaggeration trade-off described in this paper arises due to differences in precision between estimators. To illustrate this, I generate estimates from two unbiased estimators with identical mean but different variances.
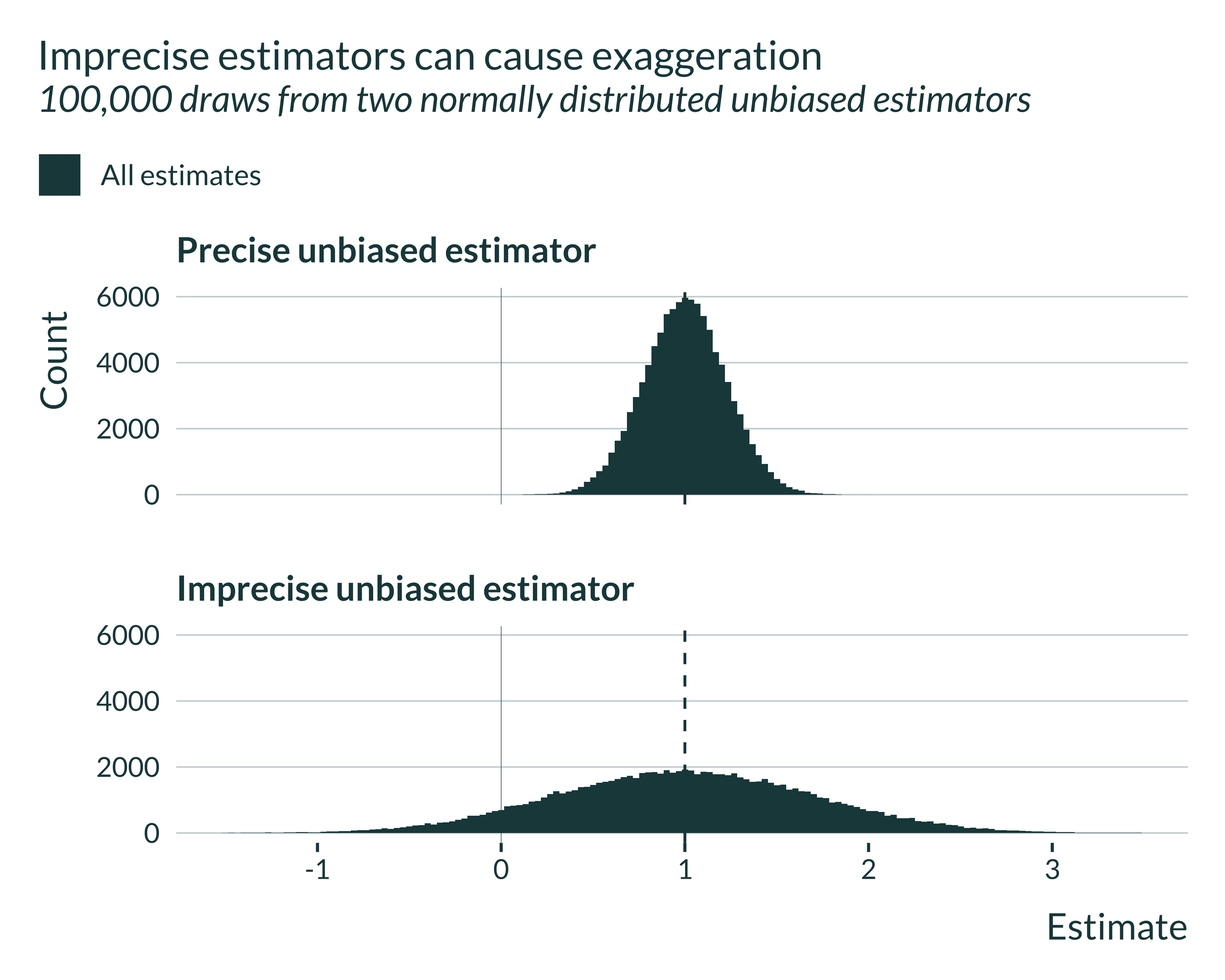
Both estimators, since unbiased, are centered on the true effect, here 1. The distribution of the imprecise estimator is by definition more spread out.
Let’s then have a look at which estimates are statistical significant and which are not. To be significant, estimates have to be at least 1.96 standard errors away from 0. Thus, for the imprecise estimator, they have to be further away from 0:
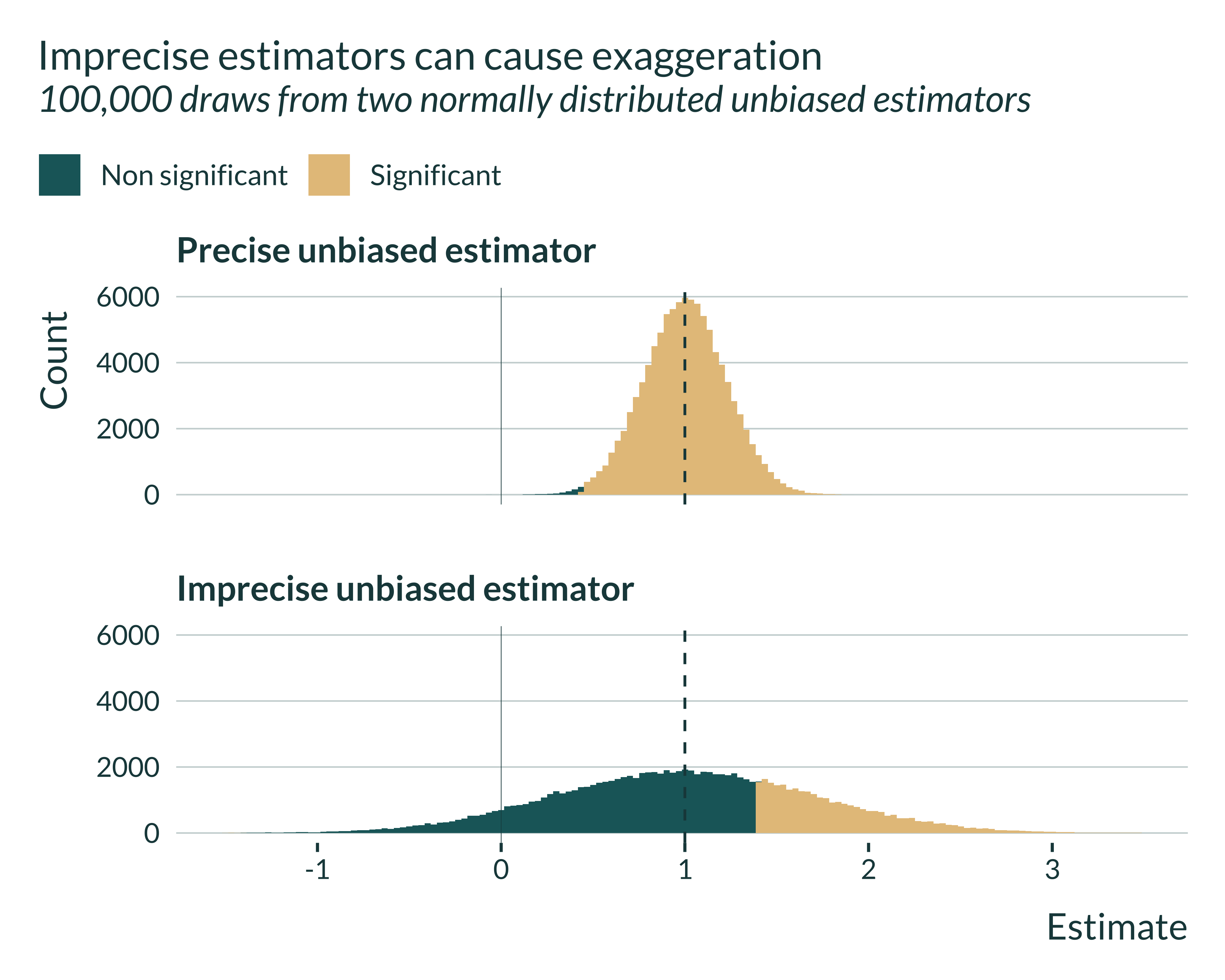
We notice that for the precise estimator, most estimates are statistically significant. The 1.96 standard errors threshold is not very far from 0. This is very different for the imprecise estimator: significant estimates are located in the tails of the distribution.
If we look at the mean of these significant estimates, it is almost equal to the true effect in the case of the precise estimator but quite different for the imprecise estimator:
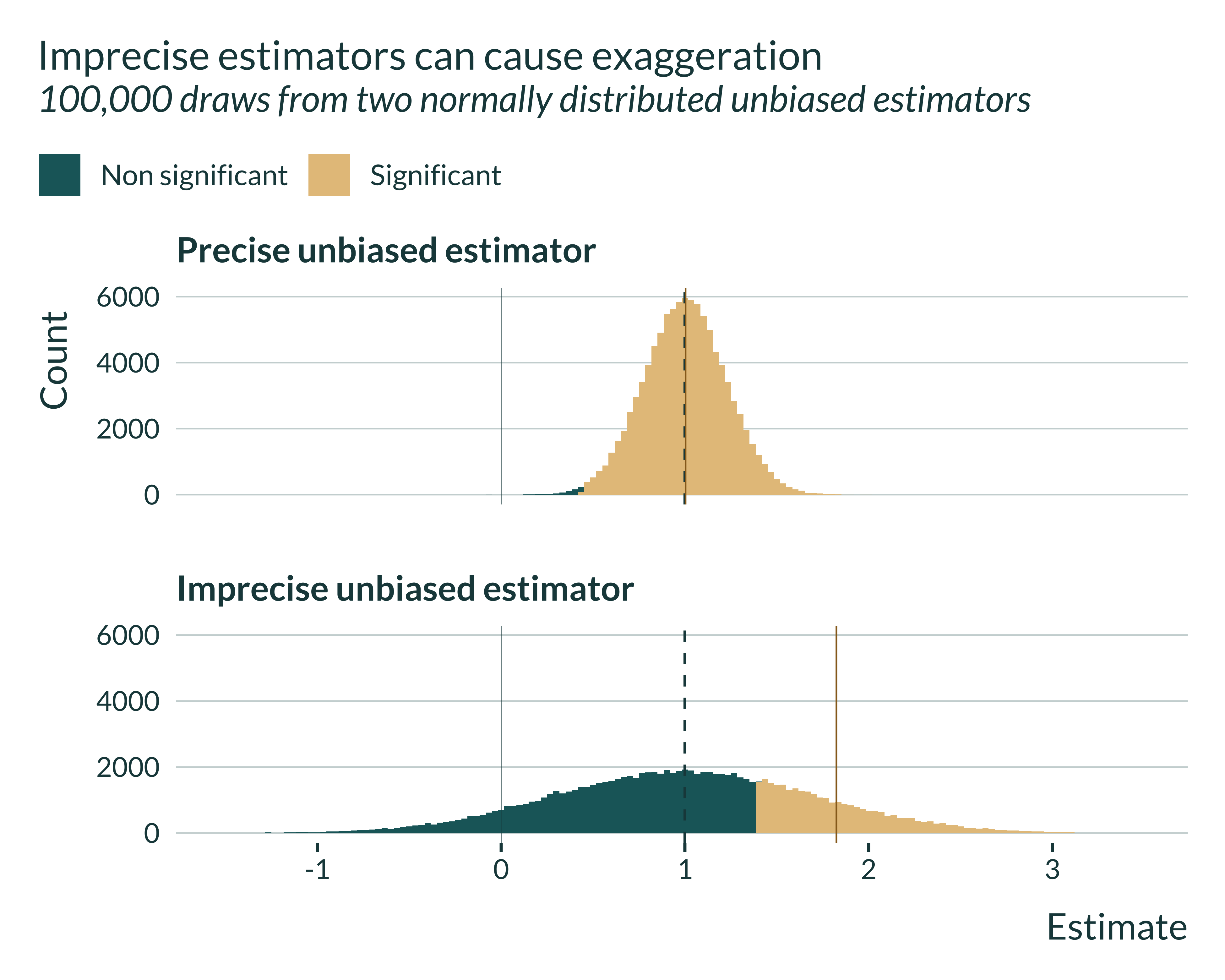
Even though the estimator is unbiased, the set of statistically significant estimates is a biased sample of the distribution.
Note that this figure also suggests that, the less precise the estimator, the larger the exaggeration.
Why don’t I provide definitive figures on the magnitude of exaggeration in the literature and my simulations?
Exaggeration is in essence impossible to measure as its computation depends on the true effect, which is always unknown. One can only hypothesize this true effect size, deriving plausible effect sizes from meta-analyses, credible studies (e.g., large RCTs), or theoretical findings.
This why I turn to simulations. Yet, while simulations allow to know the true effect size, the resulting exaggeration is quite dependent on the calibration choices and the context, preventing me from drawing definitive numerical conclusions from these analyses.
How are statistical power and exaggeration related?
There is a bijection between statistical power and exaggeration of significant estimates: the lower statistical power, the greater exaggeration.
When statistical power is low, only a few estimates are significant. They are located in the tails of the distribution and are therefore not located at the center of the distribution (the true effect, if the estimator is unbiased in the traditional sense of \(\mathbb{E}[\hat{\beta}] = \beta\)).