rallicagram
rallicagram.RmdThis vignette introduces the main functions in the package and provides examples of simple analyses that can be carried out with these functions.
More information is available in the documentation of each function,
accessible by typing help("gallicagram") in the console for
instance, for the gallicagram function.
Main functions
Occurrences
The main function in this package, gallicagram, builds a
data frame with the yearly, monthly or daily proportion of mentions of a
term in one of the corpora.
For the Le Monde corpus, this function allows to compute the
number of newspaper articles that mention the keywords (parameter
n_of = "articles").
ex_occur <- gallicagram(
keyword = "président",
corpus = "lemonde",
from = 1960,
to = 1970,
resolution = "monthly"
)Here is an example of the first rows of the output:
| date | keyword | n_occur | n_total | prop_occur | year | month | corpus | resolution | n_of |
|---|---|---|---|---|---|---|---|---|---|
| 1960-01-01 | président | 1338 | 872943 | 0.0015327 | 1960 | 1 | lemonde | monthly | 1-grams |
| 1960-02-01 | président | 1360 | 915672 | 0.0014852 | 1960 | 2 | lemonde | monthly | 1-grams |
| 1960-03-01 | président | 1461 | 928764 | 0.0015731 | 1960 | 3 | lemonde | monthly | 1-grams |
| 1960-04-01 | président | 1239 | 772707 | 0.0016035 | 1960 | 4 | lemonde | monthly | 1-grams |
| 1960-05-01 | président | 1355 | 835612 | 0.0016216 | 1960 | 5 | lemonde | monthly | 1-grams |
| 1960-06-01 | président | 1314 | 850245 | 0.0015454 | 1960 | 6 | lemonde | monthly | 1-grams |
Co-occurrences
gallicagram_cooccur builds a data frame with the yearly,
monthly or daily proportion of mentions of close co-occurrences of two
keywords in one of the three main corpora (lemonde,
livres and presse) between two specified
dates.
Close co-occurrences correspond to words that are less than 3 (4 in
the Le Monde corpus) words away in the initial text. For the
Le Monde corpus, this function allows to compute the number of
co-occurrences within an entire article (parameter
cooccur_level = "articles").
ex_cooccur <- gallicagram_cooccur(
keyword_1 = "président",
keyword_2 = "république",
corpus = "lemonde",
from = 1960,
to = 1970,
resolution = "monthly"
)Here is an example of part of the output:
| date | keyword_1 | keyword_2 | n_cooccur | n_total | prop_cooccur | year | month | corpus | resolution | cooccur_level |
|---|---|---|---|---|---|---|---|---|---|---|
| 1960-01-01 | président | république | 232 | 575465 | 0.0004032 | 1960 | 1 | lemonde | monthly | 4-grams |
| 1960-02-01 | président | république | 295 | 606116 | 0.0004867 | 1960 | 2 | lemonde | monthly | 4-grams |
| 1960-03-01 | président | république | 287 | 616477 | 0.0004655 | 1960 | 3 | lemonde | monthly | 4-grams |
| 1960-04-01 | président | république | 212 | 513816 | 0.0004126 | 1960 | 4 | lemonde | monthly | 4-grams |
| 1960-05-01 | président | république | 182 | 552610 | 0.0003293 | 1960 | 5 | lemonde | monthly | 4-grams |
| 1960-06-01 | président | république | 196 | 563800 | 0.0003476 | 1960 | 6 | lemonde | monthly | 4-grams |
Associations
gallicagram_associated builds a data frame with the
words most frequently used close to a given keyword over the period. For
the Le Monde corpus, this function allows to compute the number
of co-occurences within an entire article (parameter
distance = "articles").
ex_associated <- gallicagram_associated(
keyword = "camarade",
corpus = "lemonde",
from = 1960,
to = 1970,
n_results = 10,
distance = 3
)The terms most often associated with “camarade” are:
| associated_word | n_cooccur | keyword | corpus | from | to | cooccur_level |
|---|---|---|---|---|---|---|
| khrouchtchev | 76 | camarade | lemonde | 1960 | 1970 | 3-grams |
| mao | 47 | camarade | lemonde | 1960 | 1970 | 3-grams |
| toung | 40 | camarade | lemonde | 1960 | 1970 | 3-grams |
| ancien | 38 | camarade | lemonde | 1960 | 1970 | 3-grams |
| tse | 28 | camarade | lemonde | 1960 | 1970 | 3-grams |
| dubcek | 22 | camarade | lemonde | 1960 | 1970 | 3-grams |
| promotion | 18 | camarade | lemonde | 1960 | 1970 | 3-grams |
| ami | 16 | camarade | lemonde | 1960 | 1970 | 3-grams |
| compagnie | 16 | camarade | lemonde | 1960 | 1970 | 3-grams |
| thorez | 16 | camarade | lemonde | 1960 | 1970 | 3-grams |
Graphs
One of the main usage of Gallicagram is to plot time
series of occurrences in a corpus. The function
gallicagraph enables to do that in only one additional line
of code. It take as input a dataframe produced by one of the functions
from the package and automatically produces the corresponding graph:
# my own theme for ggplot graphs
mediocrethemes::set_mediocre_all()
gallicagram(keyword = "obama", corpus = "lemonde", from = 2005) |>
gallicagraph()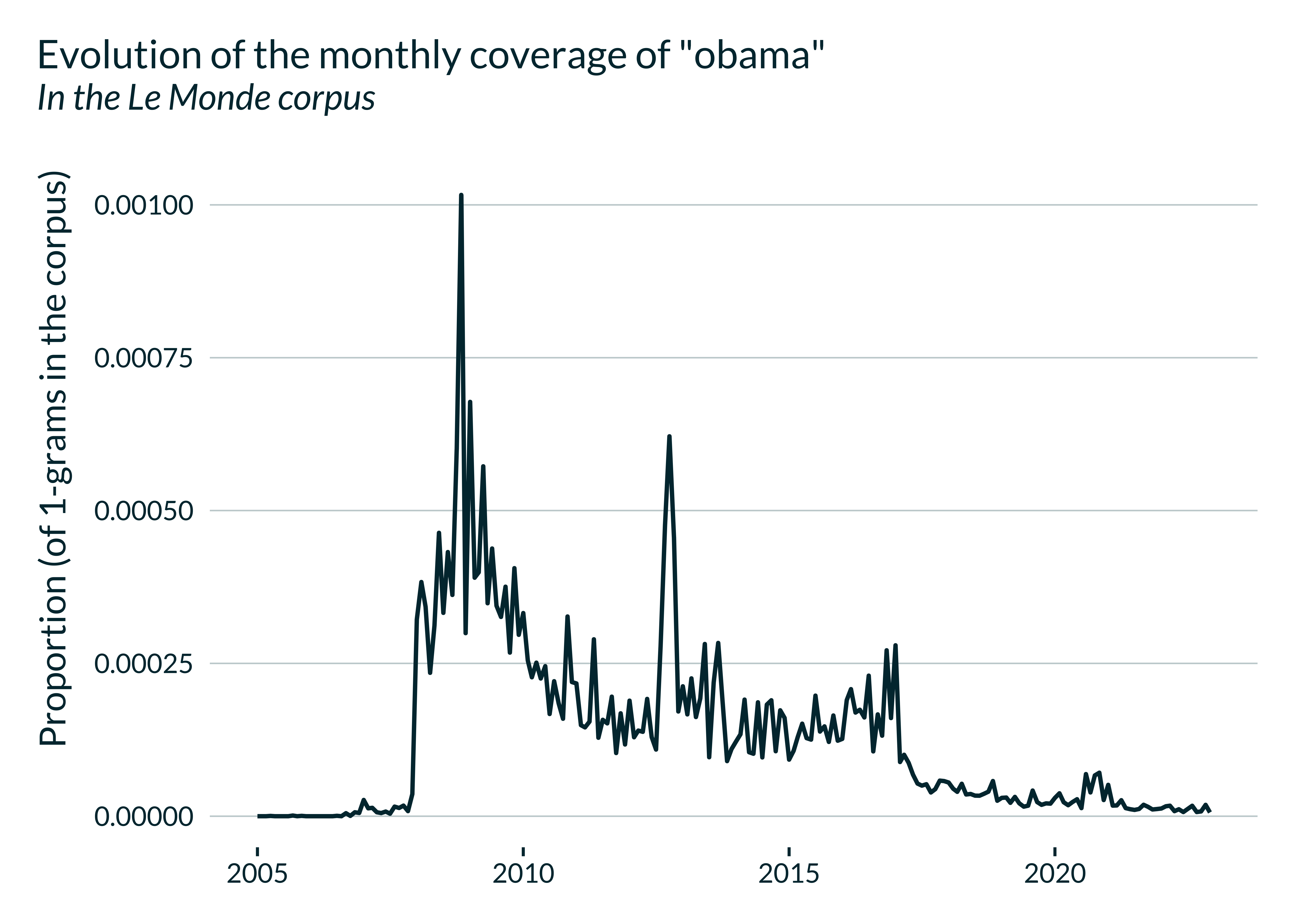
Note that I use my own ggplot theme mediocrethemes.
The use of this theme is of course not mandatory and one can remove the
line mediocrethemes::set_mediocre_all()).
One can also use the same function to plot words associated with a given keyword:
gallicagram_associated(keyword = "obama", corpus = "lemonde", from = 2005) |>
gallicagraph()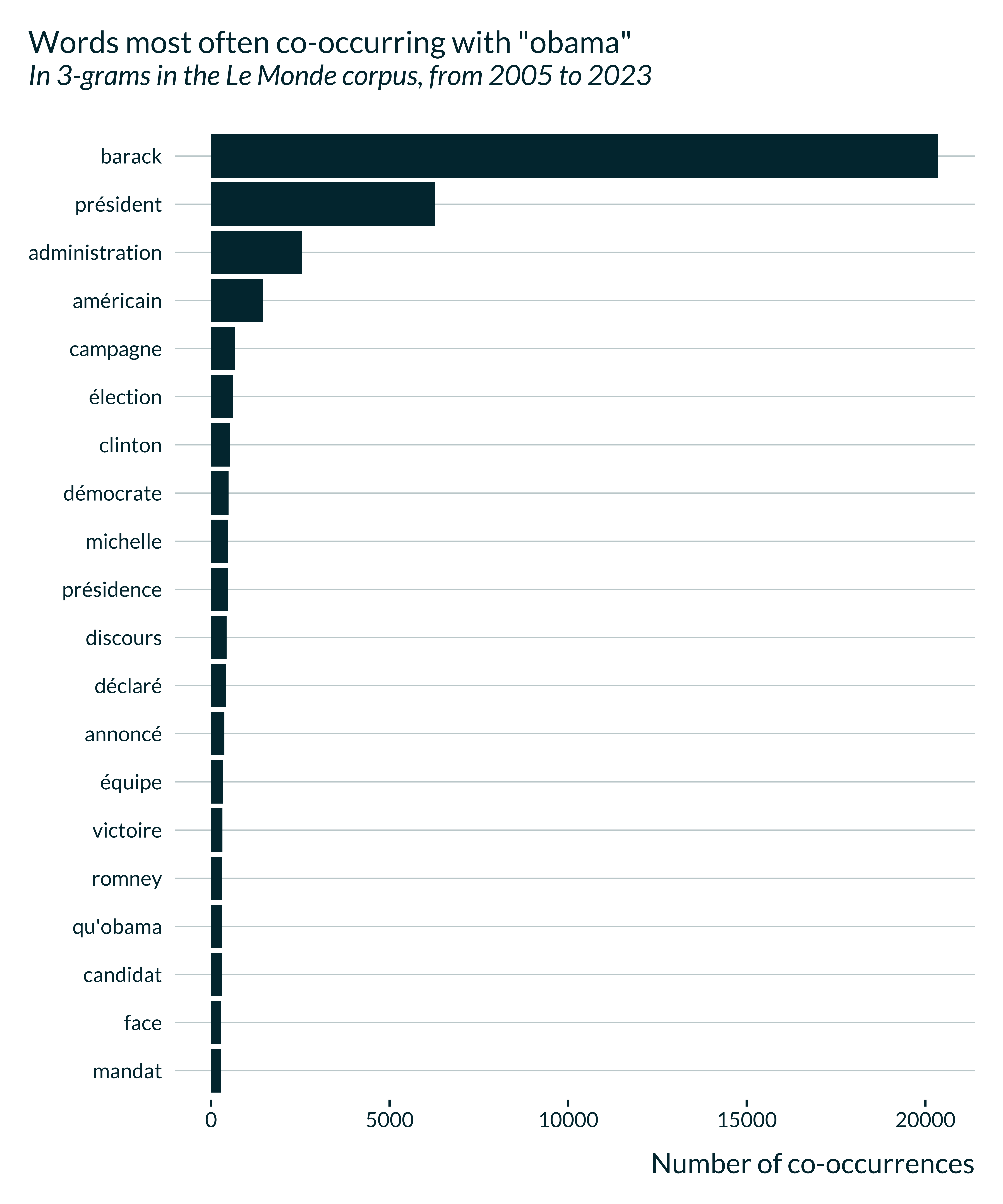
More than one keyword
Occurrences of a lexicon
Each of the main function described above has a lexicon
counterpart, adding a suffix _lexicon
(gallicagram_lexicon,
gallicagram_cooccur_lexicon and
gallicagram_associated_lexicon). Each function simply loop
the intial function over each word the lexicon(s) and sums the results.
It thus compute the sum of (co-)occurrences of each word in the
lexicon:
ex_lexicon <- gallicagram_lexicon(
lexicon = c("président", "présidente"),
corpus = "lemonde",
from = 1960,
to = 1970,
resolution = "monthly"
)
ex_cooccur_lexicon <- gallicagram_cooccur_lexicon(
lexicon_1 = c("président", "présidente"),
lexicon_2 = c("mauvais", "nul"),
corpus = "lemonde",
from = 1960,
to = 1970,
resolution = "monthly"
)Here is an example of part of the output of
gallicagram_lexicon:
| date | keyword | n_occur | n_total | prop_occur | year | month | corpus | resolution | n_of | lexicon |
|---|---|---|---|---|---|---|---|---|---|---|
| 1960-01-01 | président | 1341 | 872943 | 0.0015362 | 1960 | 1 | lemonde | monthly | 1-grams | président+présidente |
| 1960-02-01 | président | 1362 | 915672 | 0.0014874 | 1960 | 2 | lemonde | monthly | 1-grams | président+présidente |
| 1960-03-01 | président | 1465 | 928764 | 0.0015774 | 1960 | 3 | lemonde | monthly | 1-grams | président+présidente |
| 1960-04-01 | président | 1241 | 772707 | 0.0016060 | 1960 | 4 | lemonde | monthly | 1-grams | président+présidente |
| 1960-05-01 | président | 1358 | 835612 | 0.0016252 | 1960 | 5 | lemonde | monthly | 1-grams | président+présidente |
| 1960-06-01 | président | 1315 | 850245 | 0.0015466 | 1960 | 6 | lemonde | monthly | 1-grams | président+présidente |
These functions are particularly helpful to compute the number of occurrences of words from a whole lexical field (or the plural or feminine form of a keyword, etc).
Words with the same stem
The function get_same_stem() enables to retrieve part of
these forms: those that share the same stem as the keyword of interest.
For instance, for “écologie”:
get_same_stem("écologie")
#> [1] "écologie" "écologique" "écologiquement" "écologiques"
#> [5] "écologiste" "écologiste" "écologistes" "écologistes"This function is particularly useful when its output is passed to one
of the _lexicon functions:
ex_stem_lexicon <- get_same_stem("écologie") |>
gallicagram_lexicon(
corpus = "lemonde",
from = 1960,
to = 1970,
resolution = "yearly"
)Note that due to the number of requests sent to the API, it may take some time to run.
| date | keyword | n_occur | n_total | prop_occur | year | corpus | resolution | n_of | lexicon |
|---|---|---|---|---|---|---|---|---|---|
| 1960-01-01 | écologie | 4 | 10378608 | 4e-07 | 1960 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
| 1961-01-01 | écologie | 1 | 10397003 | 1e-07 | 1961 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
| 1962-01-01 | écologie | 1 | 11987113 | 1e-07 | 1962 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
| 1963-01-01 | écologie | 0 | 12223185 | 0e+00 | 1963 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
| 1964-01-01 | écologie | 12 | 12823655 | 9e-07 | 1964 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
| 1965-01-01 | écologie | 6 | 12860422 | 5e-07 | 1965 | lemonde | yearly | 1-grams | écologie+écologique+écologiquement+écologiques+écologiste+écologiste+écologistes+écologistes |
Searching several keywords
One can also run the functions for several keywords but separately,
without suming the result. To do so, one can use the function
purrr::map_dfr. It takes as parameters the vector of
keywords to search, followed by the function (gallicagram)
and additional arguments to pass to the function. It returns a unique
data frame with the results for searches corresponding to each keyword,
basically binding the dataframes produced by each keyword search.
library(purrr)
keywords <- c("république", "france")
purrr::map_dfr(keywords, gallicagram,
corpus = "lemonde", from = "1960", to = "1970")Based on that same principle, we can run several searches at once,
varying all parameters, not only the keyword searched. To do that, we
can specify the series of parameters in a data frame, each row
corresponding to a set of parameters to run the gallicagram
function for. We then pass this data frame to
purrr::pmap_dfr.
To specify the set of parameters, we can either build the parameters
data frame by hand. It is also often helpful to use
tidyr::crossing to create all combination of possible
searches.
params_pmap <-
tibble::tibble(
from = 1850,
to = 1870,
resolution = "yearly"
) |>
tidyr::crossing(corpus = c("press", "books")) |>
tidyr::crossing(keyword = c("république", "france"))The corresponding set of parameters to search looks like this:
| from | to | resolution | corpus | keyword |
|---|---|---|---|---|
| 1850 | 1870 | yearly | books | france |
| 1850 | 1870 | yearly | books | république |
| 1850 | 1870 | yearly | press | france |
| 1850 | 1870 | yearly | press | république |
We can then pass it to purrr::pmap_dfr that will call
the function gallicagram for each of the 4 sets of
parameters defined in the rows of params_pmap:
purrr::pmap_dfr(params_pmap, gallicagram)This method also applies to the other functions in the
rallicagram package.